ChatGPT起源
最近ChatGPT大火,写一篇介绍ChatGPT起源的文章来梳理一下自己对ChatGPT的理解。
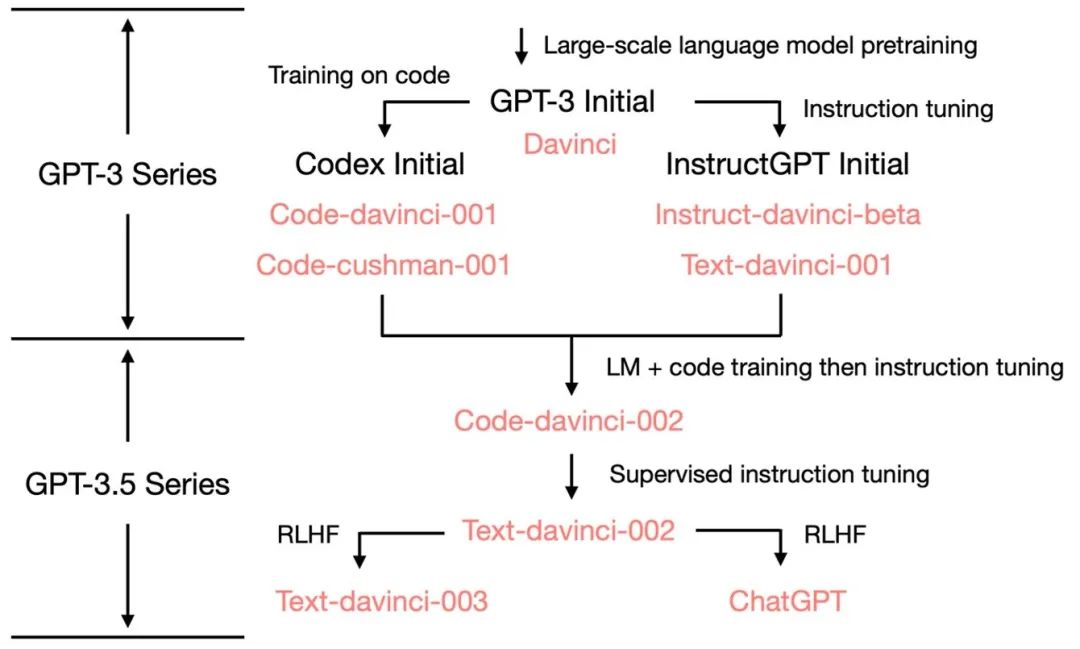 在2020年7月,OpenAI发布了模型索引为
在2020年7月,OpenAI发布了模型索引为davinci的初代 GPT-3
论文,从此它就开始不断进化。在2021年7月,Codex论文发布,其中初始的Codex是根据(可能是内部的)120亿参数的
GPT-3 变体进行微调的。后来这个 120 亿参数的模型演变成 OpenAI API
中的code-cushman-001。在2022年3月,OpenAI 发布了指令微调
(instruction tuning) 的论文,其监督微调 (supervised instruction tuning)
的部分对应了davinci-instruct-beta和text-davinci-001。在2022年4月至7月,OpenAI
开始对code-davinci-002模型进行 Beta 测试,也称其为
Codex。然后text-davinci-002、text-davinci-003和ChatGPT都是从code-davinci-002进行指令微调得到的。详细信息请参阅
OpenAI的模型索引文档。
总的来说,在 2020 - 2021
年期间,在code-davinci-002之前,OpenAI
已经投入了大量的精力通过代码训练和指令微调来增强GPT-3。当他们完成code-davinci-002时,所有的能力都已经存在了。很可能后续的指令微调,无论是通过有监督的版本还是强化学习的版本,都会做以下事情:
- 指令微调不会为模型注入新的能力 —— 所有的能力都已经存在了。指令微调的作用是解锁 / 激发这些能力。这主要是因为指令微调的数据量比预训练数据量少几个数量级(基础的能力是通过预训练注入的)。
- 指令微调将 GPT-3.5
的分化到不同的技能树。有些更擅长上下文学习,如
text-davinci-003,有些更擅长对话,如ChatGPT。 - 指令微调通过牺牲性能换取与人类的对齐(alignment)。OpenAI
的作者在他们的指令微调论文中称其为 “对齐税” (alignment
tax)。许多论文都报道了
code-davinci-002在基准测试中实现了最佳性能(但模型不一定符合人类期望)。在code-davinci-002上进行指令微调后,模型可以生成更加符合人类期待的反馈(或者说模型与人类对齐),例如:零样本问答、生成安全和公正的对话回复、拒绝超出模型它知识范围的问题。
初始的GPT3模型通过:
- 在代码上进行预训练(Codex、Copilot)
- 进行指令微调(InstructGPT)
- 基于人类反馈的强化学习(RLHF)
使得超大模型的能力开始突显出来。这一系列具有复杂理解和推理能力,在下游任务上效果明显优于GPT3的模型被称为GPT3.5系列模型。
Codex
GitHub发布了名为GitHub Copilot的服务,可以辅助程序员进行代码编写,其背后运用到的技术就是Codex。Codex实际上就是在GPT3模型上使用GitHub代码数据进行了训练,在模型上并没有创新和更改。
评价指标
在之前的文本生成工作中,主要采用的是基于匹配的方法,如BLEU。但在代码生成中,基于匹配的方法不足以评价代码功能的正确性。因此,论文中将生成代码的功能正确性作为指标,具体来说,论文中通过单元测试的方法来评测生成代码的正确性。
评价指标采用pass@k,该指标对于每个问题让模型在预测时采样生成k个样本,k个样本中任何一个通过单元测试则认为该问题被解决。论文中的具体做法是在预测时产生\(n \geq
k\)个样本,统计能够通过单元测试的正确样本数量\(c \leq
n\),并根据如下公式计算pass@k: \[pass@k :=
\underset{problems}{\mathbb{E}}[1-\frac{n-c \choose k}{n \choose
k}]\]
数据集
- Code Fine-Tuning数据集 用来做Fine-Tuning的代码数据集,从GitHub的54 million个公开代码仓库上收集了数据,共计179GB,经过过滤之后,最终数据集大小为159GB。
- Supervised Fine-Tuning数据集 从GitHub上收集的Code Fine-Tuning数据集除了独立函数之外,还包含类实现、配置文件、脚本等。这些代码和从docstring生成函数的相关性不大,因此作者认为这种数据分布的不匹配会影响模型在测试数据集上的效果。为了进行有监督的Fine-Tuning(这里的有监督指的是后续的代码是前面输入的标准答案),作者构建了一个更贴近测试集的训练数据集,数据的来源是编程比赛网站和持续合并的代码仓库,论文通过前者构造了10000个编程问题,通过后者构造了40000个编程问题。
模型
Codex的模型直接采用了GPT3,并尝试了从头训练模型和基于GPT3的参数Fine-Tuning两种方法,结果基于GPT3的参数进行微调并没有取得效果上的提升,但基于GPT3的参数微调可以使模型更快地收敛。
InstructGPT
目前OpenAI没有公布ChatGPT的技术细节,但是在其官网上提到它有一个兄弟模型InstructGPT,以下内容基于InstructGPT的论文来探究ChatGPT中的技术点。

论文导言
基于prompt的大规模语言模型在一系列的下游任务中都有惊人的表现,但与此同时,这些模型经常表现出不受人控制的行为,例如捏造事实,产生大量带有偏见或有毒的文本。作者认为产生这些现象的根本原因是训练模型时的损失函数是最大化预测下一个token的概率,这和人们期望的目标安全且有帮助的听从人的指示存在偏差,二者没有对齐。避免这些有害的行为对语言模型的实际使用至关重要。
模型
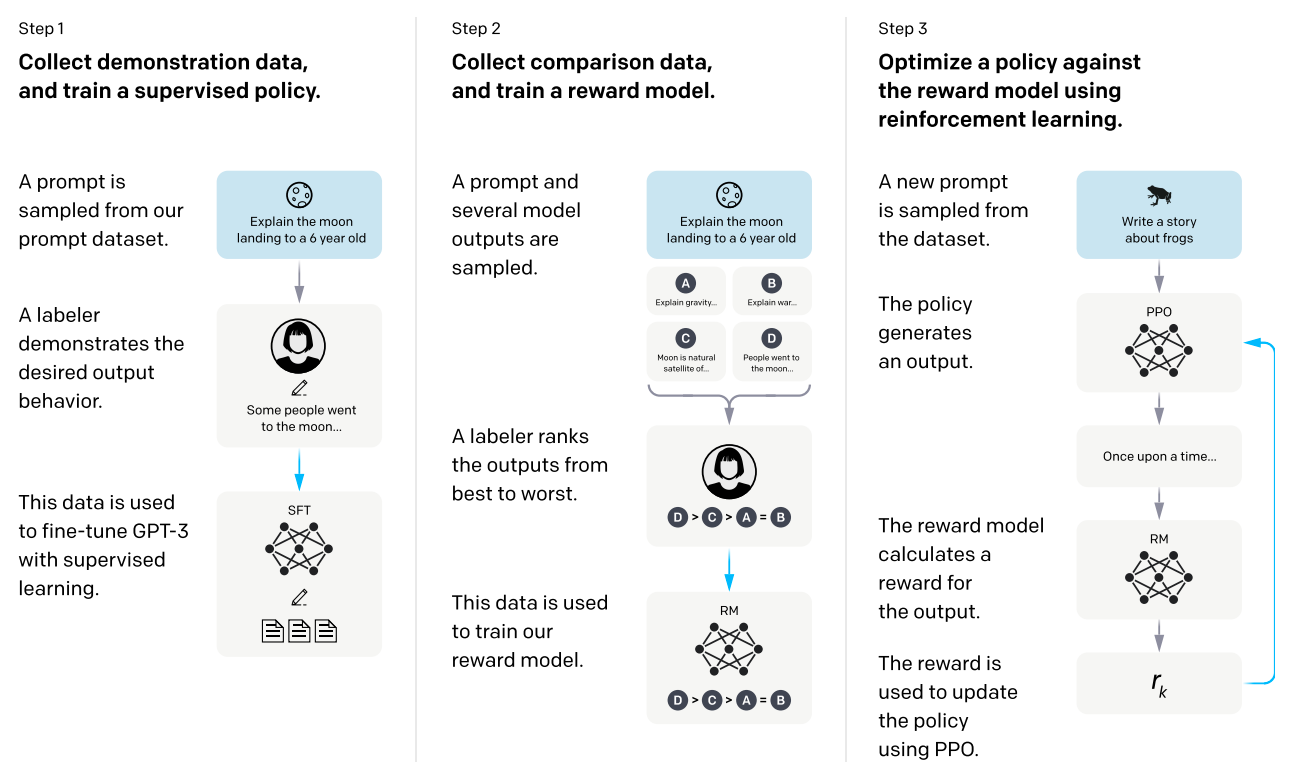
在InstructGPT模型中,作者采用来自人类反馈的强化学习(RLHF)来对GPT3进行微调,希望让GPT3的输出更符合人类的偏好,方法主要如下所示:
在ChatGPT中,方法示意图基本一致,只是GPT3变成了GPT3.5: 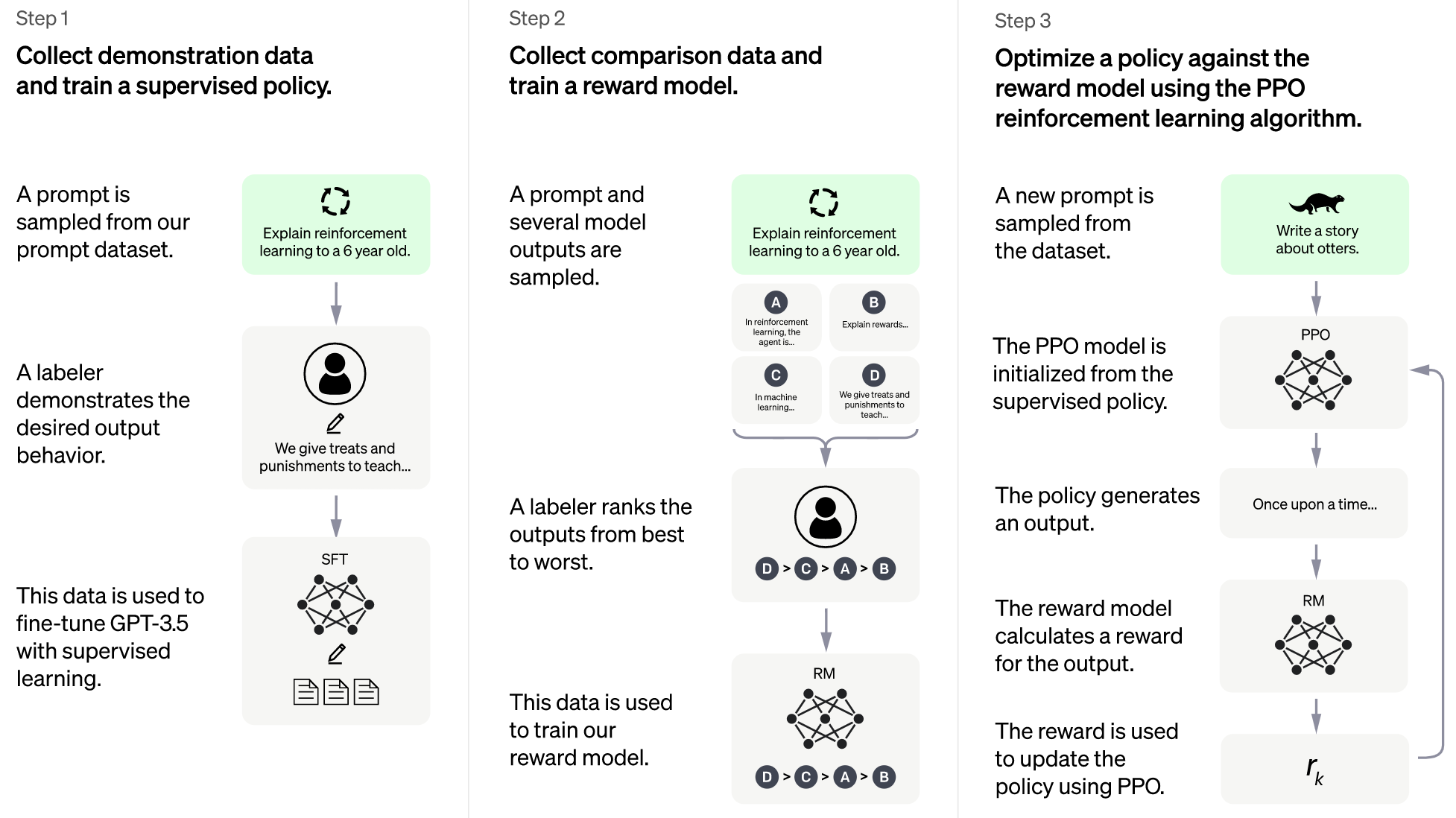
由上面的流程图可以看出,模型的训练分为以下三个步骤:
Supervised fine-tuning (SFT)\(\quad\)作者收集了来自OpenAI API和标注人员后期编写的提示(prompt),并让标注人员对这些提示编写结果。这些人工的演示数据被用于监督学习微调预训练的GPT3模型。在实验中,作者训练了16个epochs,使用了余弦学习率衰减和residual dropout。Reward modeling (RM)\(\quad\)作者使用了另一个参数量为6B的GPT-3,并将最终层替换为映射到标量的线性层,这个模型被称为reward model (RM),作者期望该模型能评价对话模型输出结果的优劣。在这一步中训练数据由SFT模型生成,对于每一个prompt,标注人员会对SFT模型产出的K个输出根据喜好程度进行排序,然后将prompt+回答输入RM模型得到分数。由于标注人员并没有直接对文本进行打分,而是进行排序,所以这里RM模型采用的损失函数为pair wise ranking loss: \[loss(\theta)=-\frac{1}{K\choose2}E_{(x,y_w,y_l)~D}[log(\sigma(r_\theta(x,y_w)-r_\theta(x,y_l)))]\] 其中\(r_\theta(x,y)\)是RM模型对于prompt \(x\)生成回答\(y\)的打分,这里我们假设\(y_w\)的排序比\(y_l\)高。\(D\)是标注人员对于当前prompt以及模型生成答案的排序结果。Reinforcement learning (RL)\(\quad\)作者在有了SFT和RM后,使用了强化学习的方式来进一步训练SFT,在这个过程中RM的输出结果会被视为强化学习的reward。强化学习使用了PPO算法,最大化如下期望: \[ objective(\phi)=E_{(x,y)~D_{\pi_{\phi}^{RL}}}[r_{\theta}(x,y)-\beta log(\pi_{\phi}^{RL}(y|x)/\pi^{SFT}(y|x))] \\ +\gamma E_{x~D_{pretrain}}[log(\pi_{\phi}^{RL}(x))] \] 其中\(\pi_{\phi}^{RL}\)是RL模型,\(\pi^{SFT}\)是第一步有监督微调得到的模型,\(D_{pretrain}\)是预训练的数据集。上式中有三项,逐项分析:- \(E_{(x,y)~D_{\pi_{\phi}^{RL}}}[r_{\theta}(x,y)]\):即强化学习模型\(\pi_{\phi}^{RL}\)要使奖励模型\(r_\theta\)的得分越高越好。
- \(E_{(x,y)~D_{\pi_{\phi}^{RL}}}[-\beta log(\pi_{\phi}^{RL}(y|x)/\pi^{SFT}(y|x))]\):计算KL散度,由于奖励模型\(r_\theta\)是在有监督学习模型\(\pi^{SFT}\)的基础上训练得来的,当\(\pi_{\phi}^{RL}\)和\(\pi^{SFT}\)相差较多时,\(r_\theta\)可能会效果变差或失去作用,因此这里使用KL散度来约束\(\pi_{\phi}^{RL}\)和\(\pi^{SFT}\)之间的距离,\(\beta\)是用来控制约束力度的超参数。
- \(\gamma E_{x~D_{pretrain}}[log(\pi_{\phi}^{RL}(x))]\):强化模型得到的模型不仅希望可以满足奖励函数,同时也希望可以保留原先在预训练阶段学习到的知识,因此作者将预训练阶段的损失也加入了模型进行训练,\(\gamma\)是权重超参。
以上三步骤使用的数据集大小如下: 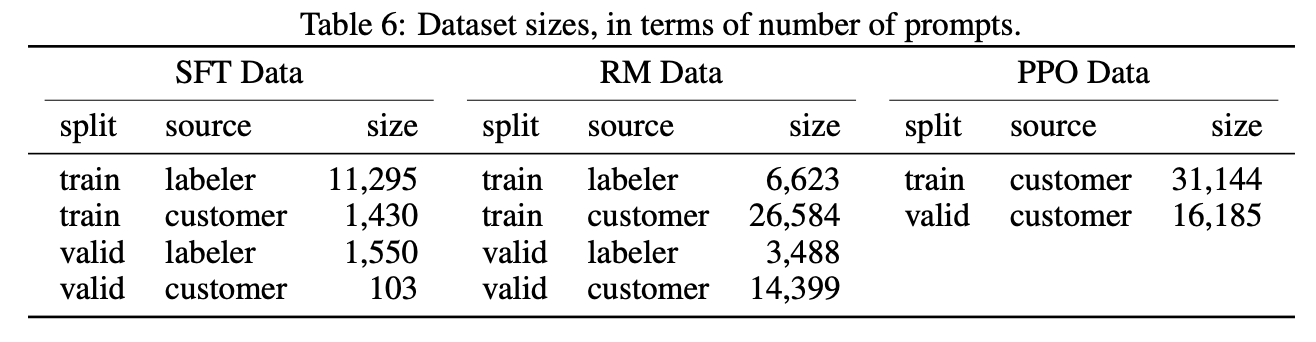 其中:
其中:
SFT dataset, 收集来自OpenAI API和标注人员后期编写的提示(prompt) + 标注人员编写的结果。RM dataset, 收集来自OpenAI API和标注人员后期编写的提示(prompt) + SFT模型编写的结果 + 标注人员对结果进行排序。PPO dataset, 收集来自OpenAI API和标注人员后期编写的提示(prompt),没有人工标注,直接输入模型进行强化学习训练。
数据的收集与标注
论文的数据主要来自两个途径:
- 由标签者编写的提示数据集。
- 在OpenAI API上提交给早期InstructGPT模型的提示数据集。 这些提示非常多样化,包括生成、问题回答、对话、摘要、提取和其他自然语言任务,数据集超过96%是英语。
对于OpenAI
API中的提示数据,作者通过检查公共前缀来启发式的删除重复提示,并设置每个用户的提示上限为200个来保证多样性,以下为来自API提示的种类分布及样例:
 为了对这些提示进行结果撰写,OpenAI雇佣了一个大约 40
人的标记团队。由于标记的任务偶尔会包含有争议和敏感的话题,OpenAI在选择标记者还从“对敏感信息的认可度”,“结果排序的合理程度”,“回复敏感提示的能力”,“不同话题下敏感问题的识别能力”这4方面进行了筛选。此外他们建立了一个入职培训流程,来指导标记者有限生成真实且无害的数据。从结果来看,尽管任务很复杂,但标记者之间的一致率相当高(约72%)。
为了对这些提示进行结果撰写,OpenAI雇佣了一个大约 40
人的标记团队。由于标记的任务偶尔会包含有争议和敏感的话题,OpenAI在选择标记者还从“对敏感信息的认可度”,“结果排序的合理程度”,“回复敏感提示的能力”,“不同话题下敏感问题的识别能力”这4方面进行了筛选。此外他们建立了一个入职培训流程,来指导标记者有限生成真实且无害的数据。从结果来看,尽管任务很复杂,但标记者之间的一致率相当高(约72%)。
ChatGPT检测器
由于ChatGPT的热度在不断提升,ChatGPT检测器也开始出现。