【文献阅读】Generating Long Sequences with Sparse Transformers
机构:OpenAI
论文地址:
前言
自从Transformer被提出以来,它依靠强大的效果得到了广泛的关注。Transformer最被诟病的一个问题是它的时间复杂度以及空间复杂度和输入序列的长度成二次方的关系\(O(n^2)\)。而这篇文章提出的Sparse Transformer方法使用稀疏自注意力替代了传统Transformer的密集自注意力,将Transformer的复杂度降低到\(O(n\sqrt{n})\)。
算法动机
在CIFAR-10数据集上,使用一个128层的自注意力模型。对注意力进行可视化,得到下图:
 图中白色区域是注意力机制的高权值位置,黑色区域是被mask掉的位置(由于是自回归生成图片,所以需要将未来信息遮掩)。
图中白色区域是注意力机制的高权值位置,黑色区域是被mask掉的位置(由于是自回归生成图片,所以需要将未来信息遮掩)。
- (a)浅层的注意力高权值点集中在当前预测点的附近,也就是说浅层的注意力更关注当前像素周围的纹理信息。
- (b)第19、20层的更关注同行和同列的像素。
- (c)深层的注意力关注图像的全局信息。
- (d)更深层的注意力关注点十分的稀疏。
那么是否可以将稀疏性引入Transformer中呢,这也就是Sparse Transformer提出的动机。
Sparse Transformer
传统自注意力
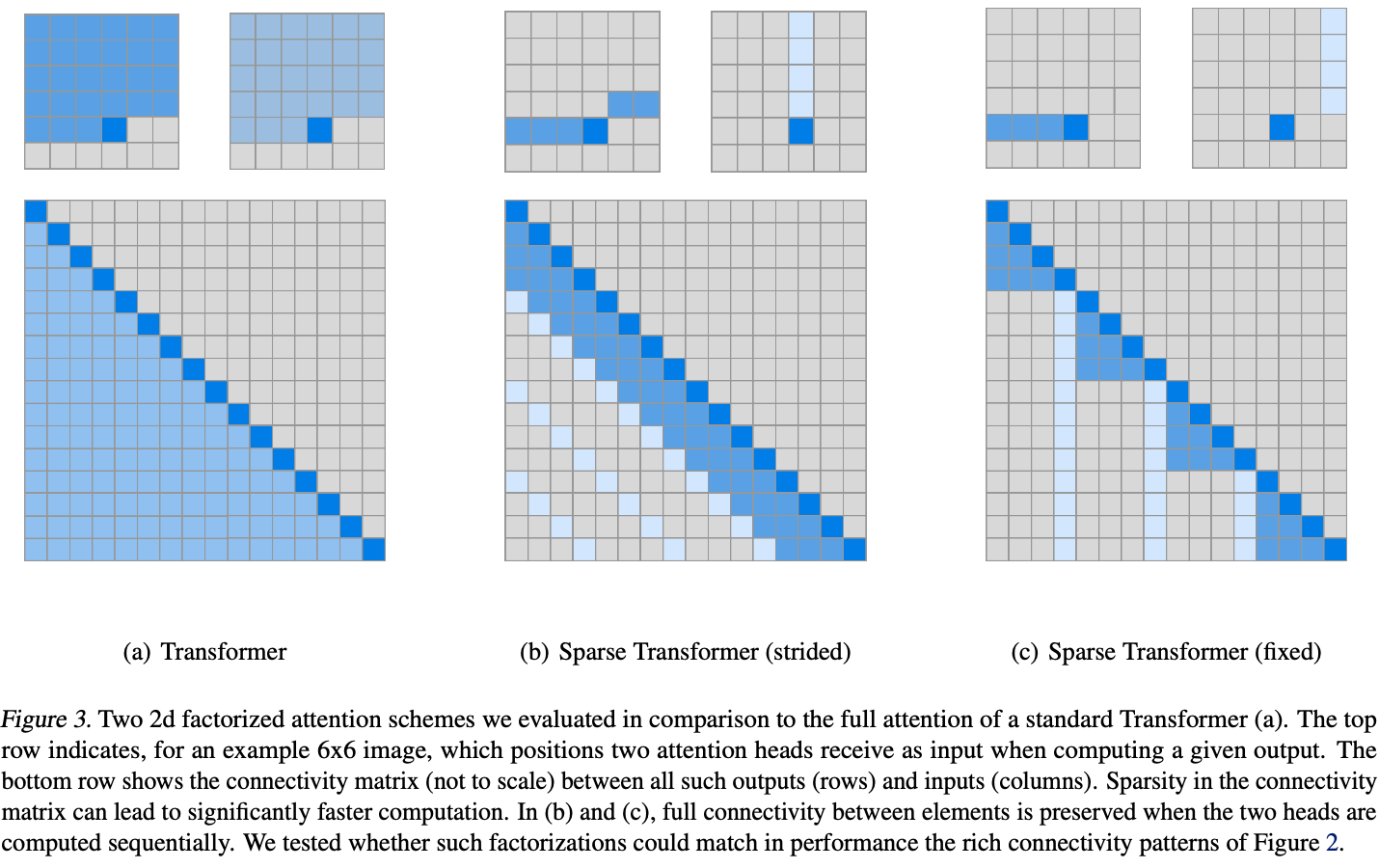
像GPT这样的自回归模型,使用的是之前所有时间片的内容来预测当前时间片的结果。传统的Transformer需要为之前的所有时间片计算一个权值,所以传统Transformer的自注意力机制的复杂度是\(O(n^2)\)。如上图(a)中为\(6 \times 6\)大小图像的注意力和长度为16的注意力连接矩阵。
Factorized Self-Attention
Transformer在进行图像生成时,注意力矩阵与注意力所处的网络深度呈现了明显的相关稀疏性。那么我们能否提前就人工设置好自注意力矩阵的稀疏性呢?这样我们一是能够引入网络结构的归纳偏置,二是能够减轻模型的计算量,提升计算速度。下面就来介绍Sparse Transformer是如何实现这个目标的。
传统的自注意力的计算方式可以表示为: \[softmax(\frac{QK^T}{\sqrt{d}})\] 该计算方式复杂度最高的地方是\(QK^T\),达到了\(O(n^2)\)。而Sparse Transformer的核心是只让设置好的像素点参与自注意力的计算(注意这里不是只选取设置好位置上的像素点,其他mask掉,因为这样斌不能降低模型的复杂度)。
为了实现上述目标,我们这里引入一个名为连接模式(Connectivity Pattern)的变量,它表示为\(S=\{S_1, ..., S_n\}\)。其中\(S_i\)表示预测第\(i\)个时间片的索引,表示为一个由0和1组成的二维矩阵,二维矩阵中的数值为1表示该位置的像素点参与自注意力的计算。如在上图中,位置为28,则传统自注意力中\(6 \times 6\)大小的\(S_{28}\)表示为(a)的上半部分,其中深色部分为1,浅色部分为0。
在Sparse Transformer的自注意力计算中,连接模式只作用在\(K\)和\(V\)的计算上,计算过程如下所示。
- 对于第\(i\)个时间片的输入,首先使用\(key\)和\(value\)的权值矩阵乘以输入特征,得到\(K\)和\(V\)。然后再将连接模式\(S_i\)作用到\(K\)和\(V\)上,得到稀疏的特征\(K_{S_i}\)和\(V_{S_i}\)。 \[K_{S_i}=(W_kx_j)_{j \in S_i}, V_{S_i}=(W_vx_j)_{j \in S_i}\]
- 然后使用稀疏特征得到第\(i\)个时间片的自注意力结果。 \[a(x_i,S_i)=softmax(\frac{(W_qx_i)K_{S_i}^{T}}{\sqrt{d}})V_{S_i}\]
- 最后再将\(n\)个时间片的结果合并起来,得到最终的结果。 \[Attend(X, S)=(a(x_i, S_i))_{i \in \{1,...,n\}}\]
其中\(W_q\),\(W_k\)以及\(W_v\)分别是\(Query\),\(Key\),\(Value\)三个向量对应的权值矩阵。Sparse Transformer通过让连接模式作用到\(K^T\)上,从而降低了\(QK^T\)的复杂度。
我们这里已经定义好了稀疏自注意力机制的通用计算方式,接下来要做的就是设计不同的连接模式。对于每个自注意力的计算,我们可以使用若干不同的注意力核。在论文中,作者使用了2个注意力核(行+列),也可以扩展到更高的维度。
Strided Attention
Strided
Attention由两种形式的连接模式组成,如上图(b)所示,其包含行和列两种注意力核。假设步长为\(l\),行注意力核指的是在连接模式中,当前时间片的前\(l\)个时间片的值是1,其余的值是0.列注意力核指的是连接模式中每隔l个时间片的值为1,其余值为0。
行注意力核和列注意力核的表达式如下: \[
\begin{matrix}
A_i^{(1)}=&\{t,t+1,...,i\}, t=max(0, i-l) \\
A_i^{(2)}=&\{j:(i-j) \space mod \space l = 0\}
\end{matrix}
\] 对于图片生成这一类任务来说,\(l\)一般为图像的宽或者高。所以复杂度为\(O(l)=O(\sqrt{n})\)。
Fixed Attention
Fixed Attention同样也是由行注意力核和列注意力核组成,如上图中(c)所示。行注意力核是当前时间片同行的的时间片。表示为下面的式子: \[A_i^{(1)}=\{j:(\lfloor j/l \rfloor=\lfloor i/l \rfloor)\}\]
列注意力核表示为: \[A_i^{(2)}=\{j:j \space mod \space l \in \{t,t+1,...,l\}\}\] 其中\(t=l-c\),Fixed Attention的列注意力核又被叫做滑窗注意力核,超参数\(c\)相当于滑窗卷积窗口的大小。上述两个注意力核的复杂度同样为\(O(\sqrt{n})\)。
Factorized attention heads
上面介绍了多种不同形式的注意力核,下面将介绍如何既那个这些不同形式的注意力核融入到网络中。
传统的Transformer通过如下方式计算注意力核: \[attention(X) = W_p \cdot attend(X,S)\] 本文作者提出了一下三种新的方式:
- 每个残差块使用不同的注意力核类型,一个深层网络是由多个连续的残差块组成的,对于每个残差块,我们可以使用不同类型的注意力核,表示为下式: \[attention(X)=W_p \cdot attend(X, A^{(r \space mod \space p)})\]
- 第二个方式是每个注意力头都计算所有类型的注意力核,然后合并他们的结果,如下式所示: \[attention(X)=W_p \cdot attend(X,\bigcup_{m=1}^{p}A^{(m)})\]
- 第三个方式是对于多头的注意力机制,每组头选择一个形式的注意力核,然后将他们合并起来,如下式所示: \[attention(X)=W_p(attend(X,A)^{(i)})_{i \in \{1,...,n_h\}}\] 其中\(n_h\)组不同的注意力核会并行计算,然后在特征维度进行特征拼接。实验结果证明这种方式是最好的融合策略。