字形特征的提取方法总结
最近做了一些提取字符形状特征的工作,这里进行一下总结。
字形特征提取,即提取字符的形状特征,对于形状相似的字符,其字形特征在向量空间上应该接近,而形状不相似的字符特征在向量空间上应该远离。
如木、本,治、冶这些形近字应该接近,而木、的这种不相似的字则应远离。
字形特征的提取具体分为以下方法。
统计方法
数据处理
汉语字符主要可以分为结构和笔划两个部分,其中结构包括上下结构,左右结构等。具体的结构划分如下表所示:
| 编码 | 字符 | 意义 | 例字 | 序列 |
|---|---|---|---|---|
| U+2FF0 | ⿰ | 两部件由左至右组成 | 相 | ⿰木目 |
| U+2FF1 | ⿱ | 两部件由上至下组成 | 杏 | ⿱木口 |
| U+2FF2 | ⿲ | 三部件由左至右组成 | 衍 | ⿲彳氵亍 |
| U+2FF3 | ⿳ | 三部件由上至下组成 | 京 | ⿳亠口小 |
| U+2FF4 | ⿴ | 两部件由外而内组成 | 回 | ⿴囗口 |
| U+2FF5 | ⿵ | 三面包围,下方开口 | 凰 | ⿵几皇 |
| U+2FF6 | ⿶ | 三面包围,上方开口 | 凶 | ⿶凵㐅 |
| U+2FF7 | ⿷ | 三面包围,右方开口 | 匠 | ⿷匚斤 |
| U+2FF8 | ⿸ | 两面包围,两部件由左上至右下组成 | 病 | ⿸疒丙 |
| U+2FF9 | ⿹ | 两面包围,两部件由右上至左下组成 | 戒 | ⿹戈廾 |
| U+2FFA | ⿺ | 两面包围,两部件由左下至右上组成 | 超 | ⿺走召 |
| U+2FFB | ⿻ | 两部件重叠 | 巫 | ⿻工从 |
对于笔划部分,我们可以先将字符拆分成偏旁和部首,如下所示:
| 编码 | 字符 | 序列 | 编码 | 字符 | 序列 | 编码 | 字符 | 序列 |
|---|---|---|---|---|---|---|---|---|
| U+4F60 | 你 | ⿰亻尔 |
U+6D4B | 测 | ⿰氵则 |
U+4E20 | 丠 | ⿱北一 |
| U+662F | 是 | ⿱日𤴓 |
U+9010 | 逐 | ⿺辶豕 |
U+4E58 | 乘 | ⿻禾北 |
| U+6A1F | 樟 | ⿰木章 |
U+98D3 | 飓 | ⿺风具 |
U+4E6A | 乪 | ⿺乙田 |
| U+75C5 | 病 | ⿸疒丙 |
U+4E03 | 七 | ⿻㇀乚 |
U+4EC1 | 仁 | ⿰亻二 |
然后我们可以通过递归的方法得到各个字符的笔划,如下所示:
| 编码 | 字符 | 序列 |
|---|---|---|
| U+75C5 | 病 | ⿸⿰⿱丶㇀⿱丶⿰丿一⿱一⿻⿰丨𠃌⿰丿乀 |
| U+6D4B | 测 | ⿰⿳丶丶㇀⿰⿱⿰丨𠃍⿰丿乀⿰丨亅 |
| U+6A1F | 樟 | ⿰⿻一⿲丿丨乀⿱⿱⿱⿱丶一⿰丶丿一⿱⿴⿵⿰丨𠃍一一⿻一丨 |
这里以樟为例,解释如果通过递归的方法由偏旁部首得到笔划。
- 首先
樟由⿰木章组成,这样就得到了字符的三个组成部分⿰、木和章。 - 对于结构
⿰我们保持不变,对于木和章我们递归执行上述的拆分步骤,如章可进一步被拆分为⿱立早。 - 继续递归执行上述拆分步骤,直到达到停止条件或者不可拆分为止。
这样,我们就将字符拆分成结构和笔划组成的序列了。
字符相似度计算
有了字符的结构和笔划的组成序列之后,我们就可以计算字符之间的相似度了。这里我使用了编辑距离来进行计算。
如字符木的序列构成为⿻一⿲丿丨乀,字符本的序列构成为⿻⿻一⿲丿丨乀一,它们的编辑距离为2。则最终相似度计算如下:
\[similarity(木, 本)=1 - \frac{dis(木, 本)}{max(len(木), len(本))}=1 - \frac{2}{max(6, 8)}=0.75\]
OCR
数据构造
OCR流程分为几个部分,分别为:
- 文本检测
- 文本方向检测
- 文本识别
这里由于我们只需要提取字形的特征,可以通过自行构造数据省略“文本检测”和“文本方向检测”两个步骤,即文本位置和文本方向都是给定的,我们只需要提取固定区域的字形特征就可以了。
具体来说,对于字符A,我们可以通过字体文件(ttf、otf)将其转化为图片。
这里以刀隶体为例,转化的图片如下:

我们也可以多使用几种字体,增加模型的泛化性,如像素体的图片如下:

为了省略“文本检测”和“文本方向检测”的步骤,我们需要将字符按比例放在图片的正中央,且不要对字符进行旋转。在inference阶段提取字形特征时我们也要使用相同的设置。
模型结构
模型这里使用了Res50,结构图如下:
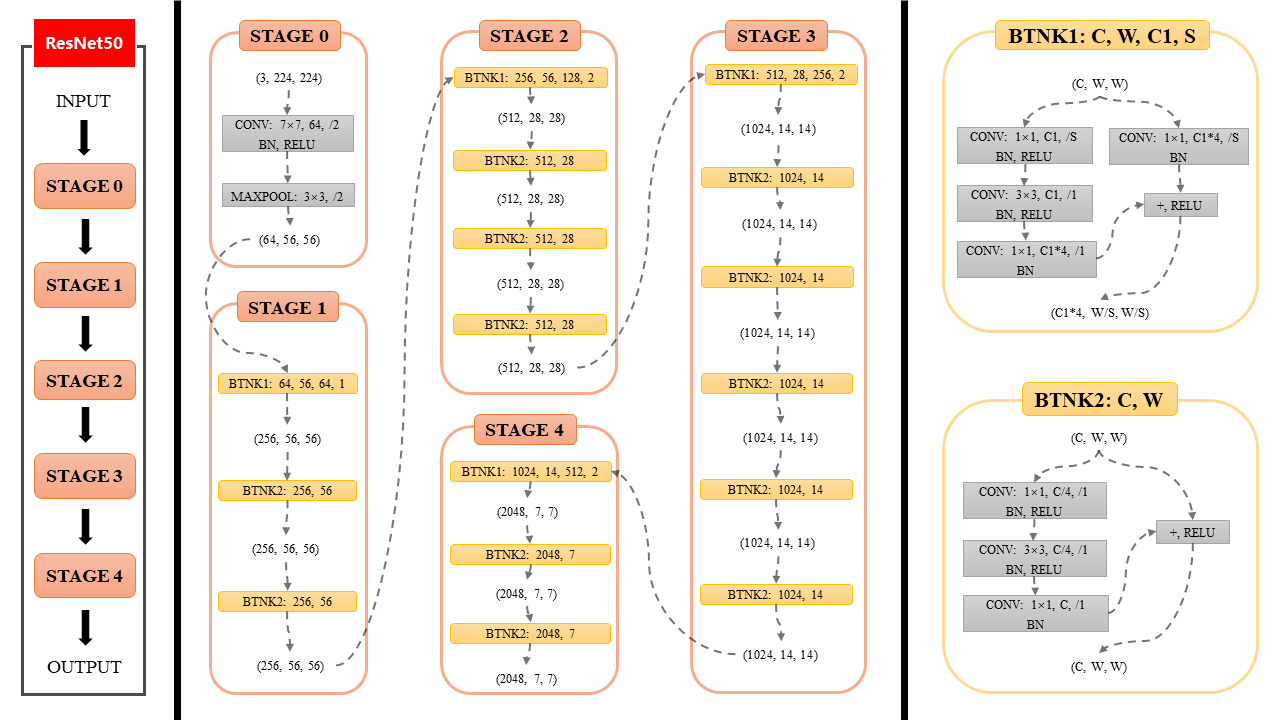
最后将字符图片分类为对应的字符即可,是一个多分类问题。
结果
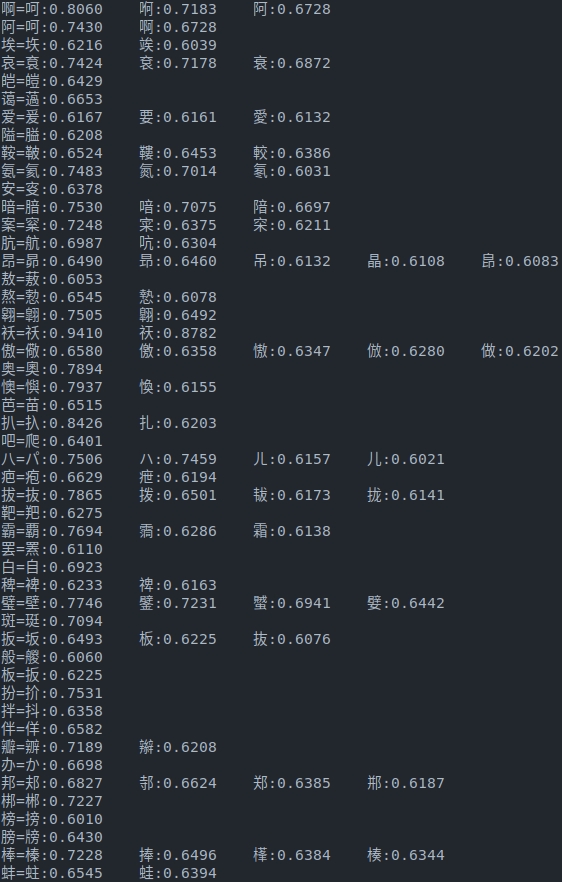
计算得到字形特征之后,可计算各个字符之间的形状相似度,也可以将字形特征用于下游任务。
计算字符相似度如下:
对比学习
先回忆一下对比学习的方法:
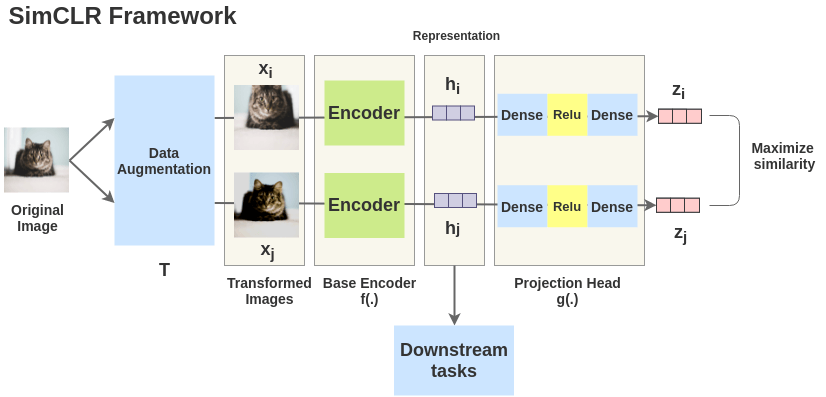
SimCLR
人类是可以通过对比来学习特征知识的,如下图所示:

通过给定左边猫的图像,人类可以通过对比得到右边哪一张图像是猫,哪一些不是。那么是否可以让机器也学会对比,通过区分相似样本和不相似样本来得到图像、文本的特征——对比学习。
SimCLR的流程如下所示,一张图像经过不同的数据增强得到两张不相同但具有相同语义的图像\(x_i\)和\(x_j\)。然后这两张图像通过一个Encoder得到中间向量表征\(h_i\)和\(h_j\),之后中间向量表征再通过一个非线性层得到向量表征\(z_i\)和\(z_j\)。最后去最大化这两张具有相同语义信息的图像的向量表征\(z_i\)和\(z_j\)来优化模型。
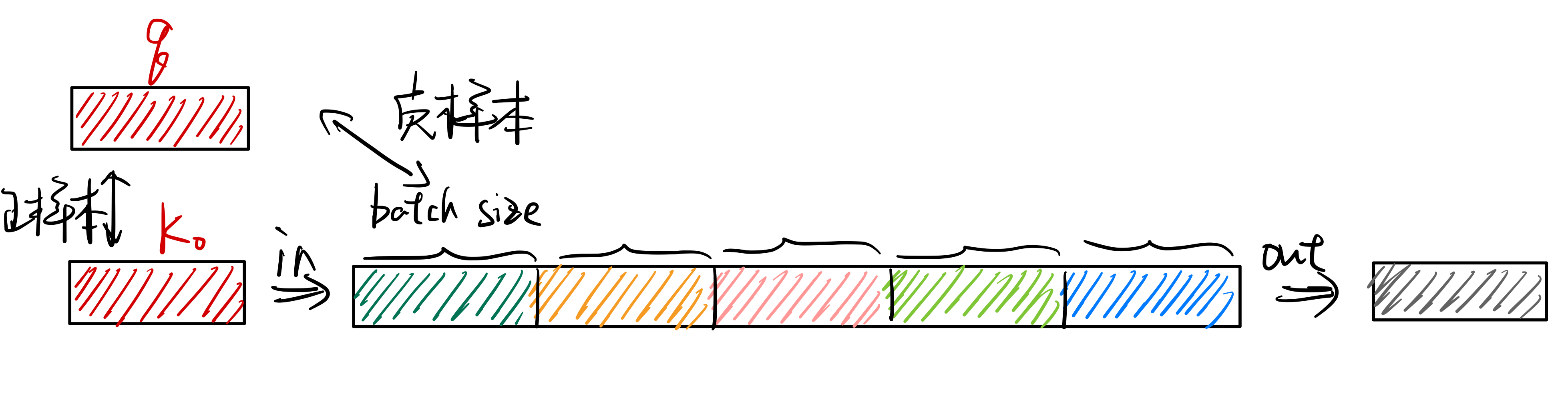
但是上面只通过正样本进行学习是没有办法将模型训练起来的,这是因为只用正样本对会使模型学到一个捷径解,即不管输入什么,都输出相同的向量表示,这样就会造成模型坍塌。所以需要同时加入正样本对和负样本对,这里的负样本数据来自同一个\(batch\)中不匹配的数据。这里以\(batch\_size=2\)为例:
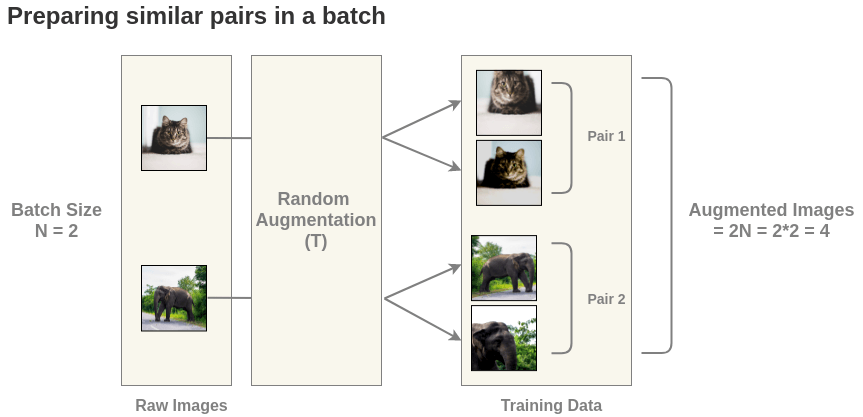
这样就得到了\(2N=4\)张图像,对每一个图像对算相似度得到相似度矩阵,需要最大化正样本对的相似度。


SimCLR的损失函数为InfoNCE: \[l(i, j) = -log\frac{exp(s_{i, j})}{ \sum_{k=1}^{2N} {}_{[k!= i]} exp(s_{i, k})}\] \[L = \frac{1}{2\textcolor{skyblue}{N}} \sum_{k=1}^{N} [l(2k-1, 2k) + l(2k, 2k-1)]\] \[s_{i,j}=\frac{z_i^Tz_j}{\tau||z_i||||z_j||}\]
首先计算图像i对图像j的损失:
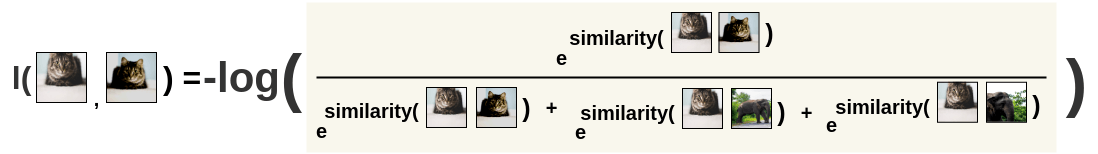
然后交换位置,再算一次,保持对称性:

最后将所有对的损失求平均:
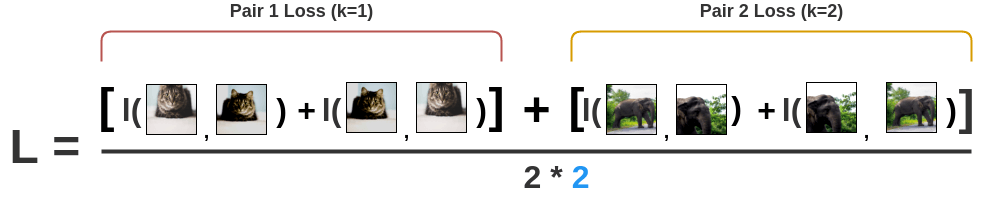
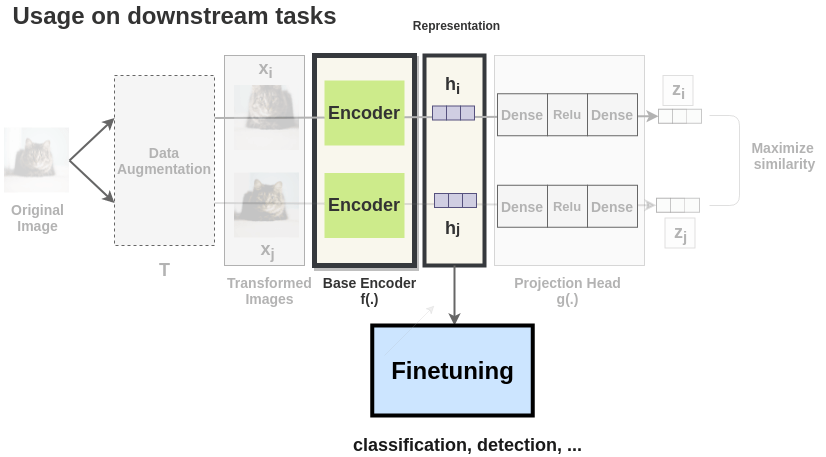
当SimCLR训练完成后,就可以将模型冻住,使用中间向量特征完成下游任务。
MoCo
MoCo和SimCLR不同的地方主要有两个方面:
- 负样本并不是在同一个batch中取,而是通过一个队列进行存储,从而将负样本数量和batch size解耦。
- 正负样本的编码器并没有共享参数,而是使用动量更新的方法来更新负样本编码器。
MoCo通过使用队列将负样本存储起来,如下图所示。将最新得到的负样本特征加入队列,并将最早的负样本特征移出队列,从而去维护一个负样本队列。这样负样本的数量就是队列的大小,队列中的负样本可以来自多个batch。
但是使用队列存储负样本就会出现一个问题,每个不同batch的数据都是来自不同时刻的模型,如下图所示:
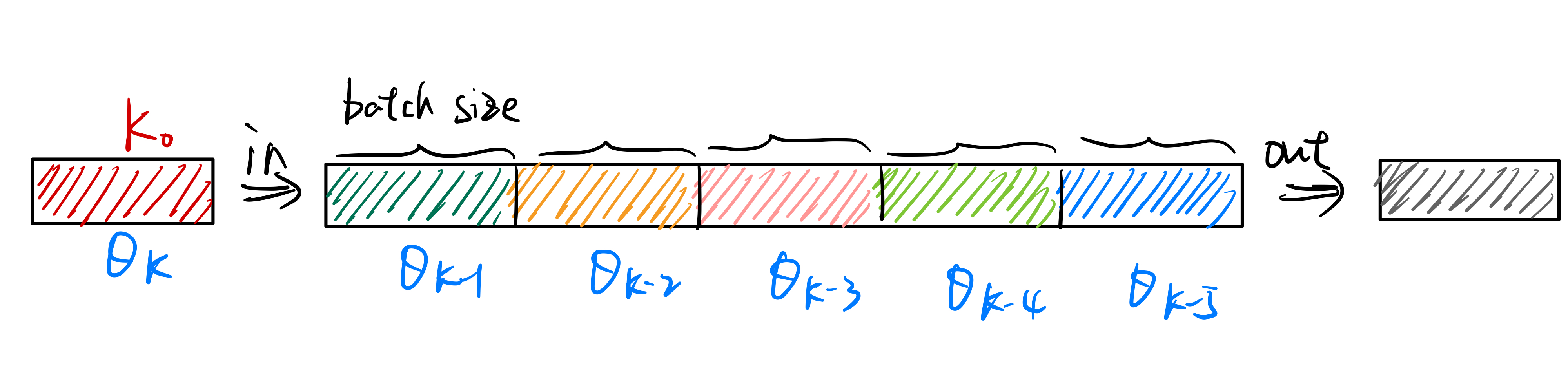 如果像simCLR一样直接将\(\theta_q\)的参数复制给\(\theta_k\),即\(\theta_k \leftarrow
\theta_q\),则会出现负样本队列中数据特征不一致的问题。因为负样本队列中的数据来自不同的batch,而且\(\theta_q\)是根据梯度在快速更新的,如果\(\theta_k\)的参数也快速更新,则队列中\(\theta_{k-1}\)、\(\theta_{k-2}\)等模型得到的特征分布会和\(\theta_k\)的得到的特征分布有很大的区别,这样模型就会学到一个捷径解,即根据特征分布的不同来区分正负样本,而不是理解样本的语义信息。
因此,MoCo在这里使用了动量更新来改变\(\theta_k\)模型的参数: \[\theta_k = m\theta_{k-1} + (1-m)\theta_q\]
从而使\(\theta_k\)模型缓慢更新,保证了队列中负样本队列中特征分布的一致性。在论文中,作者将\(m\)设为了0.999。
如果像simCLR一样直接将\(\theta_q\)的参数复制给\(\theta_k\),即\(\theta_k \leftarrow
\theta_q\),则会出现负样本队列中数据特征不一致的问题。因为负样本队列中的数据来自不同的batch,而且\(\theta_q\)是根据梯度在快速更新的,如果\(\theta_k\)的参数也快速更新,则队列中\(\theta_{k-1}\)、\(\theta_{k-2}\)等模型得到的特征分布会和\(\theta_k\)的得到的特征分布有很大的区别,这样模型就会学到一个捷径解,即根据特征分布的不同来区分正负样本,而不是理解样本的语义信息。
因此,MoCo在这里使用了动量更新来改变\(\theta_k\)模型的参数: \[\theta_k = m\theta_{k-1} + (1-m)\theta_q\]
从而使\(\theta_k\)模型缓慢更新,保证了队列中负样本队列中特征分布的一致性。在论文中,作者将\(m\)设为了0.999。 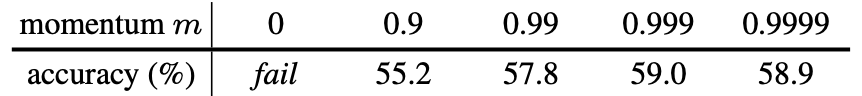
字形特征提取中的对比学习与方法改进
方法
通过对比来学习字符的字形特征表示如下图所示:
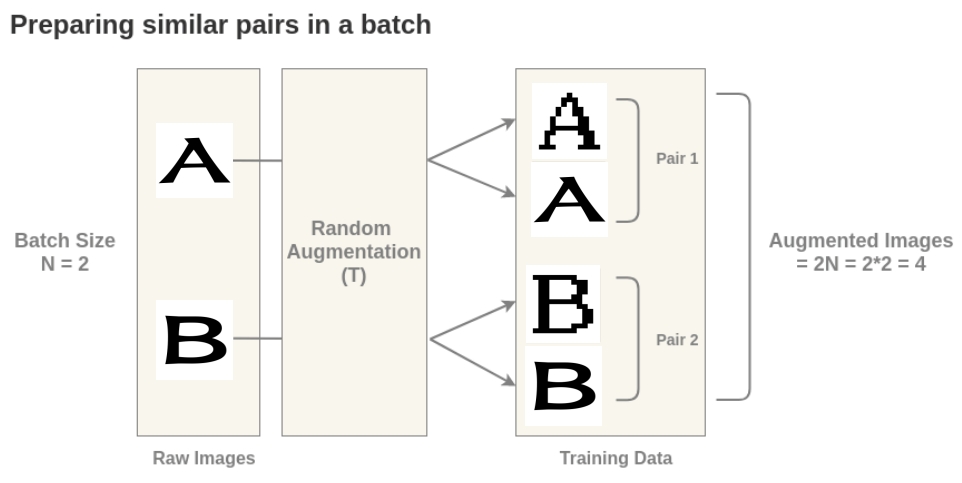
对比学习的重点就是构建正样本对,在字符特征提取中,将相同字符在不同字体中的写法构建为正样本对。即字符A在刀隶体和在像素体中的图片可以被视为正样本对,一个batch中的不同字符则视为负样本。如下图所示:
模型
和OCR中一样,模型使用Res50,结构图如下:
不同的是,这里不再是多分类问题,而是把任务构建成一个对比学习问题。
改进
上述说的对比学习方法基本都是针对图像分类的特征提取,有些方法在提取字符特征中是不适用的,因此需要对上面说的方法进行改进。
特征层的选取
当SimCLR训练完成后,就可以将模型冻住,使用中间向量特征完成下游任务。
而在字形特征的选取中,由于需要使用字符的特征计算相似度,所以下层特征更加适合,即特征\(z_i,z_j\)优于特征\(h_i,h_j\)。
负样本的选取
在MoCo中,维护了一个负样本队列,将最新得到的负样本加入队列,将最早的负样本移出队列。但在字形特征提取中,由于我们构造正样本对是相同字符的不同写法,所以上述维护负样本队列的方法会引入噪声。
如下图所示:
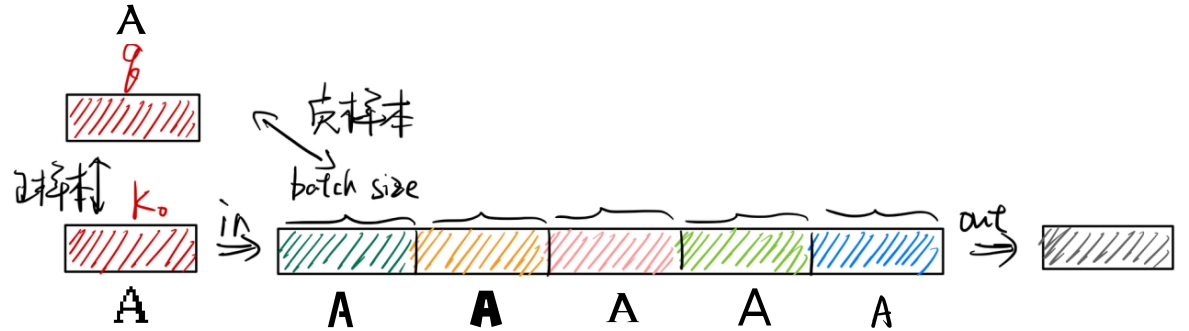
当前Batch中的正样本对为A的不同写法,但可能A的其他写法已经在之前的批次中被加入了负样本队列中,这样负样本队列中其实存在着当前Batch的正样本,导致模型效果变差。
所以对负样本队列进行如下改造(如下图所示):
- 将负样本队列大小设置为字符数大小。
- 不再是将最新的负样本加入队列,最早的负样本移出队列。而是将当前最新的负样本在对应的位置更新。
- 计算损失时将负样本队列中当前Batch对应的字符去除。
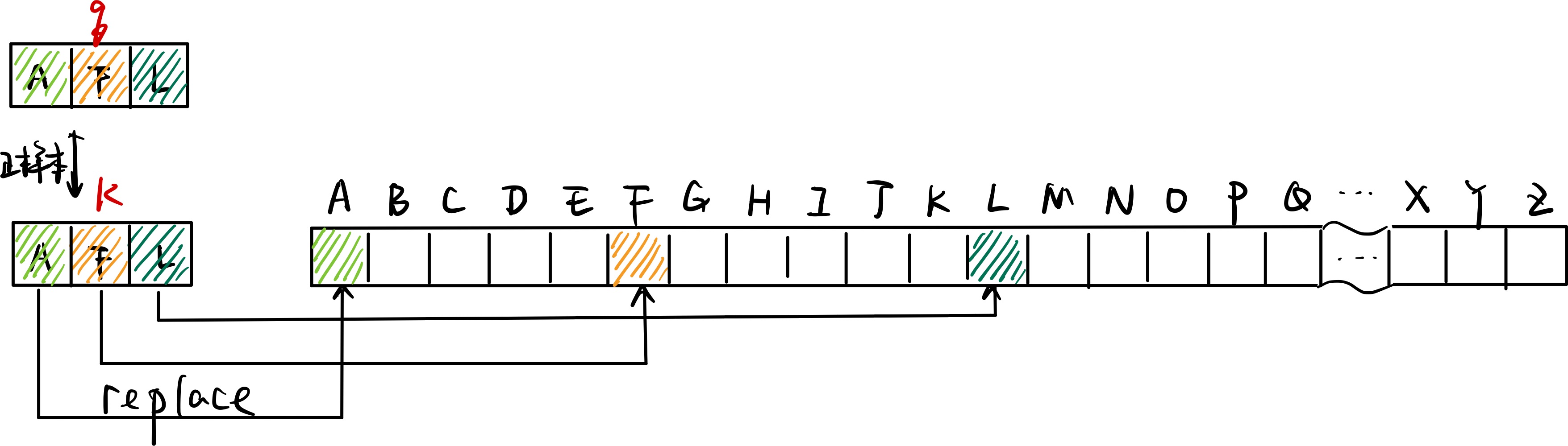
结果
计算得到字形特征之后,可计算各个字符之间的形状相似度,也可以将字形特征用于下游任务。
计算字符相似度如下:

需要进一步解决的问题
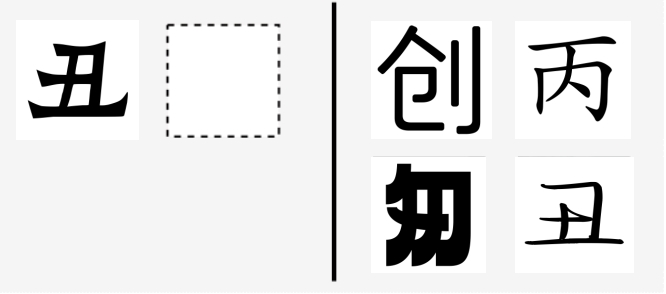
- 在Unicode字符中存在很多不同字符但在形状上却十分相似。如
𝓐、A,𝟬、0,ㄠ、幺这些字在形状上是完全一样的,但却是完全不同的字符,因此会被当作负样本对处理。这就在训练过程中引入了噪声,对模型的效果造成了影响。 - 目前字符集包含了中日韩的100多种字体,覆盖了大部分中日韩字符。但对于其他小语种(如阿拉伯语、维吾尔语)的字符覆盖还不够,需要丰富字体文件的种类和数量。