【文献阅读】MQA和GQA
MQA(Multi Query Attention)和GQA(Grouped Query Attention)是在Attention上加速大模型计算的tricks,可以缩短模型训练周期和加快推理速度。
论文地址:
- MQA: Fast Transformer Decoding: One Write-Head is All You Need
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
参考:
https://mp.weixin.qq.com/s/_4OxoRLxhOcjGf0Q4Tvp2Q
模型优化
先来看一下MHA(Multi Head Attention)、MQA(Multi Query Attention)和GQA(Grouped Query Attention)的区别:
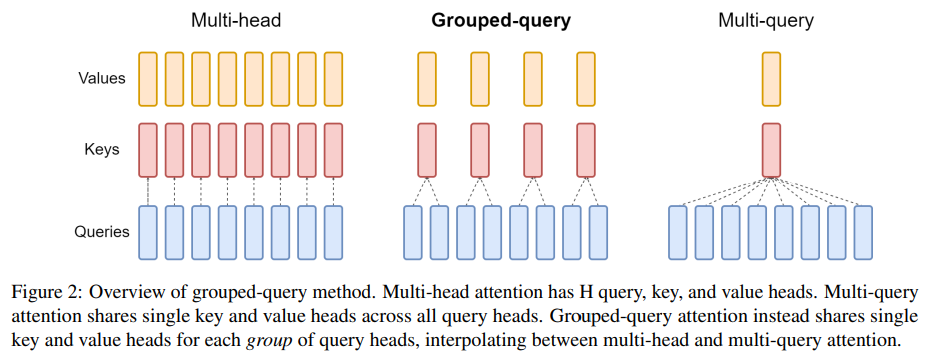
首先是原始的MHA(Multi Head Attention),QKV三部分有相同数量的头,且一一对应。每次做Attention,每个头的QKV只需要做好自己部分运算就可以了,输出时各个头concat起来就行了。
MQA(Multi Query Attention)是让Q保持原来的头数,但K和V变成只有一个,即所有头的Q共享一组K和V。但这种方法稍微会带来一些性能降低。 当然相对它能带来的收益,性能的些微降低是可以接受的。实验发现一般能提高 30%-40% 的吞吐。
GQA(Grouped Query Attention),是MHA和MQA的折中方案,既想获得MQA的MQA带来的加速效果,又不想损失太多性能。 具体思想是,Q仍然保持原来的头数,KV的头数减少为g个。多个头的Q共享一组KV,如图中就是两个Q共享一组KV。
LLAMA2中给出了效果对比,如下:
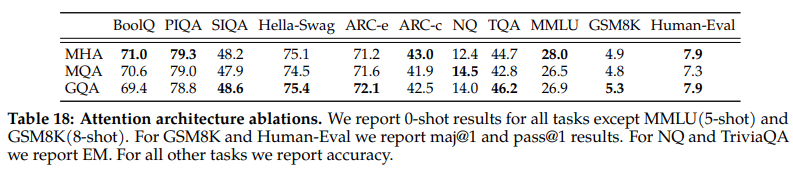
但是从上面的图来看,MQA和GQA的运算量和MHA其实是一样的,那么为什么会带来加速效果呢?这就要说到冯诺依曼架构和Memory Wall。
冯诺依曼架构和Memory Wall
预备知识
目前大模型基本上用的都是Transformer结构,Transformer包括Encoder和Decoder两个部分。
先来看Encoder部分,Encoder可以理解为AE模型,每个timestep的token可以看到所有timestep的token,因此是可以并行得到每个timestep的输出的,即一次inference得到所有timestep的结果。
而Decoder部分相当与是AR模型,每个timestep的输入是上一个timestep的输出,所以没法并行输出所有timestep的结果,只能一个一个的向后生成。
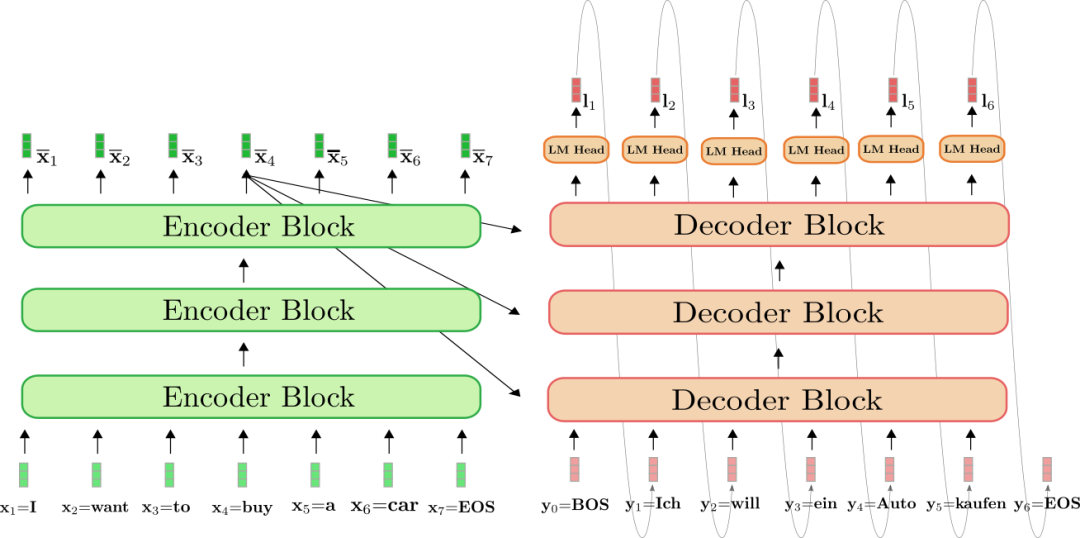
当然上述问题也有优化手段,如使用KV Cache。
Decoder的每次前向过程中,当前timestep之前的KV值都是计算过的,只是之前每次前向完成后计算结果都被丢掉了,只保留了最后的输出结果。于是一个很自然的想法就是Cache,每次前向完,将KV都保留下来,用于之后计算。代码如下:
1 | #q、k、v 当前 timestep 的 query,key,value |
但在大模型时代,上述办法存在缺陷。比如LLaMa 7B模型,hidden_size是4096,那么每个timestep需缓存参数量为\(4096 \times 2 \times 32=262144\),假设半精度保存就是512KB,1024长度那就要512MB。而现在英伟达最好的卡H100的SRAM缓存大概是 50MB,而A100则是40MB,KV计算值完全存不进缓存。
而且目前SRAM太贵了,我们没有办法直接做大SRAM内存呢,所以这条路现在是不太行的。于是退一步,放不进缓存可以放DRAM上去,而DRAM内存也就是我们常说的GPU显存。 但DRAM读取到计算芯片和SRAM读取到计算芯片的速度,差了一个量级,这会让计算芯片一直在等待数据读取。
现在我们遇到了当今芯片领域,冯诺依曼架构下最大的一个问题,也就是:Memory Wall(内存墙)。
加速原理
冯诺依曼架构包含四个部分:输入,输出,计算单元,加上存储单元。
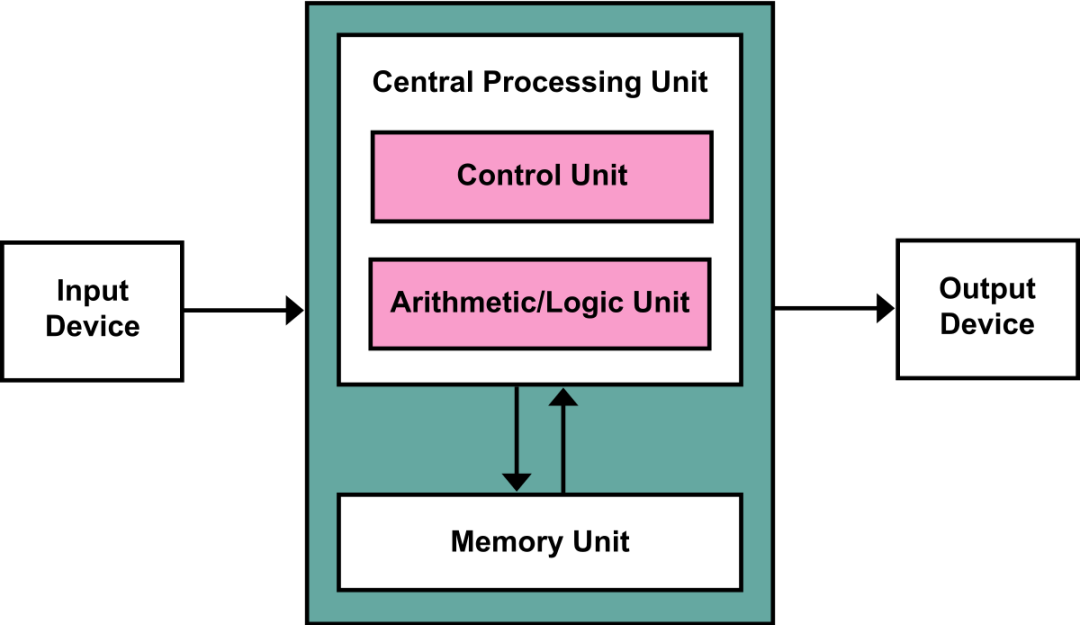
现在随着摩尔定律的见顶,虽然计算和内存的发展速度在变缓,但这并不是最大的问题,最大的问题是存储单元与计算单元间的交互。
冯诺依曼架构需要先从内存中调取数据,送入计算单元进行处理,但现在计算单元的速度是显著提升的,而从内存中读取数据的速度却没跟上,所以计算和内存这里就形成了一个瓶颈。因为短板效应,内存读取速度限制了整体速度。计算单元能很快将数据处理完,但新数据却还没到,于是就只能等待,造成利用率不高。这就是内存墙。
因为内存墙问题,现在的大模型训练,一张A100卡计算单元的利用率到四五十就不错了,用上各种技巧优化到60%已经很高了。而对于H100卡问题会更严重,因为它的计算速度相对A100提高了6倍,而内存读取带宽只增加了1.6倍,所以也要大量优化来提高利用率。
内存墙怎么越过呢?
硬件层面上,比如现在已在使用的HBM(高速带宽内存)提高读取速度,或者更彻底些,抛弃冯诺依曼架构,改变计算单元从内存读数据的方式,不再以计算单元为中心,而以存储为中心,做成计算和存储一体的“存内计算”。
软件层面上的话,最近的很多优化,比如Flash Attention,Paged Attention都可以算。Flash Attention就是减少了计算Softmax时从DRAM内存读取数据次数,从而提高了效率。
同样,MQA和GQA也是一个软件层面上翻墙的一个方法。MQA和GQA形式在推理加速方面,主要是通过两方面来完成:
- 降低了从内存中读取的数据量,所以也就减少了计算单元等待时间,提高了计算利用率。
- KV cache变小了,也就是显存中需要保存的tensor变小了,空出来空间就可以加大batch size,从而又能提高利用率。
如果要用MQA和GQA,可以是从头训练的时候就加上,也可以像GQA论文里面一样,用已有的开源模型,挑一些头取个mean用来初始化MQA或GQA继续训练一段时间。