【文献阅读】Mixtral of Experts
Mistral 7B
论文地址:
论文代码:
论文主页:
Mixtral 8x7B
论文地址:
论文代码:
论文主页:
Mixtral of
Experts这篇论文介绍的是Mixtral 8x7B,而Mixtral 8x7B和Mistral 7B的结构基本是一样的。所以在介绍Mixtral 8x7B之前,首先来看看Mistral 7B。
Mistral 7B
Mistral 7B基于transformer架构,具体参数如下。
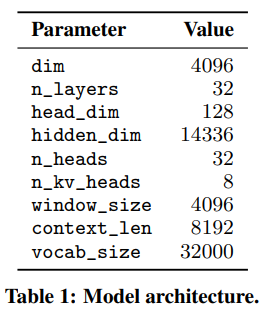
在此基础上,使用了下面的一些优化手段。
GQA
GQA可参考这里。
Sliding Window Attention

Rolling Buffer Cache
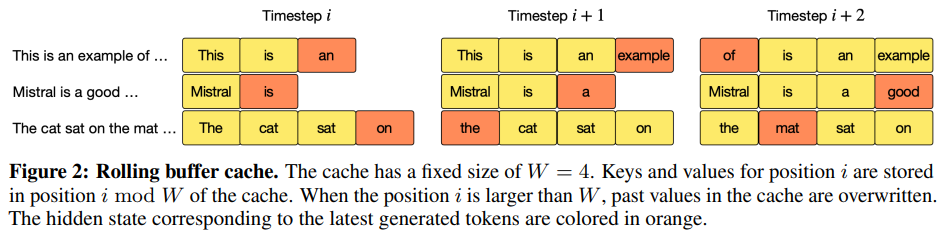
Pre-fill and Chunking

Mixtral 8x7B
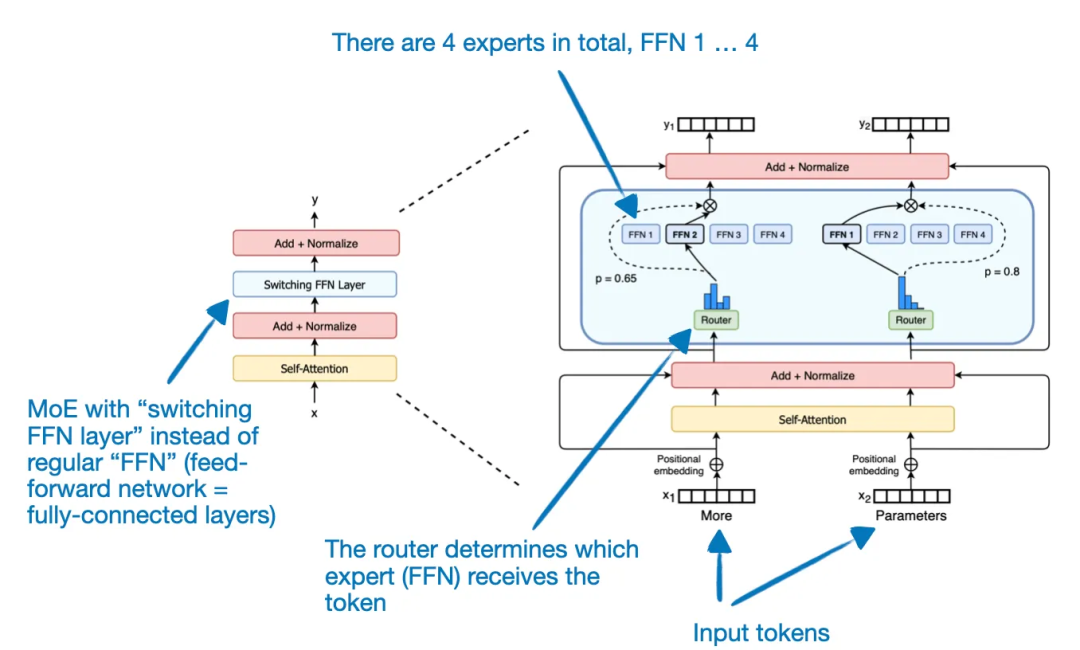
Mixtral 8x7B 并不是有8个Mistral 7B模型,名字中的8代表8个专家,所以Mixtral 8x7B 是一种稀疏专家混合模型 (SMoE)。
Mixtral 8x7B同样基于transformer架构(细节参考Mixtral 7B),然后将Feed Forward Network(FFN)替换为Mixture of Expert Layer(MoE)就得到了Mixtral 8x7B。具体参数如下:
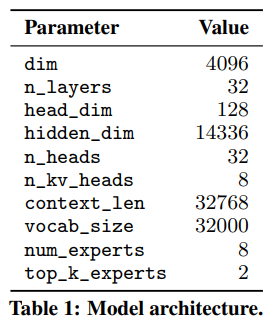
Sparse Mixture of Experts
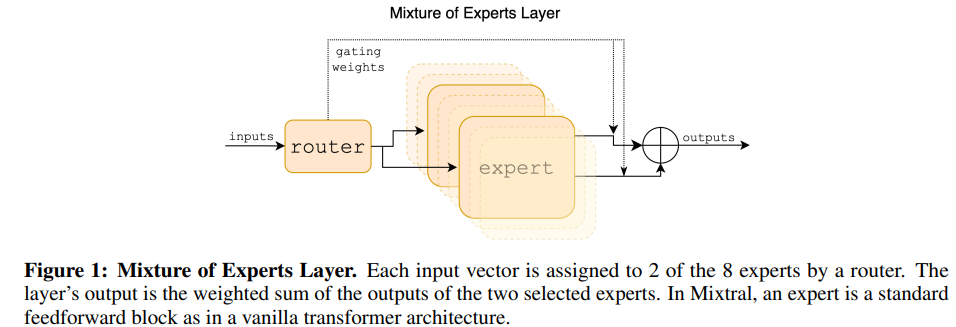
给定n个专家网络\({E_0, E_1,...,E_{n-1}}\),则MoE的输出可以用如下公式表示:
\[\sum_{i=0}^{n-1}G(x)_i \cdot E_i(x)\]
其中,\(G(x)_i\)表示第\(i\)个专家网络的门控,\(E_i(x)\)表示第i个专家网络的输出。
论文中使用了如下方法来实现门控网络:
\[G(x)=Softmax(TopK(x \cdot W_g))\]
然后使用SwiGLU来实现专家网络:
\[E_i(x)=SwiGLU_i(x)\]
最终,MoE网络的输出就可以表示为如下式子:
\[y=\sum_{i=0}^{n-1}Softmax(TopK(x \cdot W_g))_i \cdot SwiGLU_i(x)\]
其中K是可以设置的超参数,表示每个step选取多少个专家网络的结果参与计算。
Mixtral 8x7B总体流程如下: