【文献阅读】LST: Ladder Side-Tuning for Parameter and Memory Efficient Transfer Learning
论文地址:
论文代码:
如Adapter Tuning、P-Tuning、Prompt Tuning、Prefix Tuning、LoRA之类的方法,能够通过只微调很少的参数来达到或接近全量参数微调的效果。然而,这些技巧通常只是“参数高效”而并非“训练高效”,因为它们依旧需要在整个模型中反向传播来获得少部分可训练参数的梯度,说白了,就是可训练的参数确实是少了很多,但是训练速度并没有明显提升。
而LST这篇论文,通过特殊的模型构建方式,使得模型的训练速度也可以的到提升。
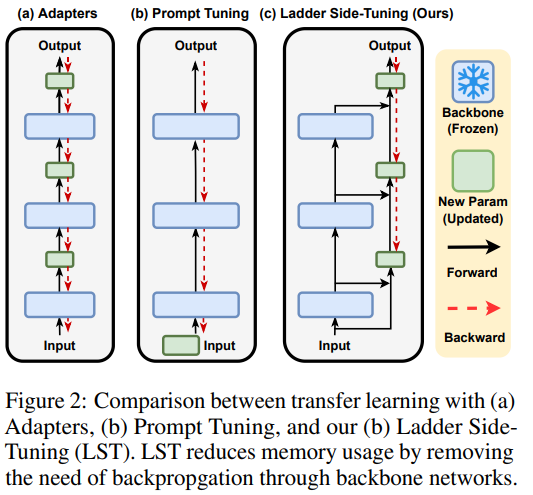
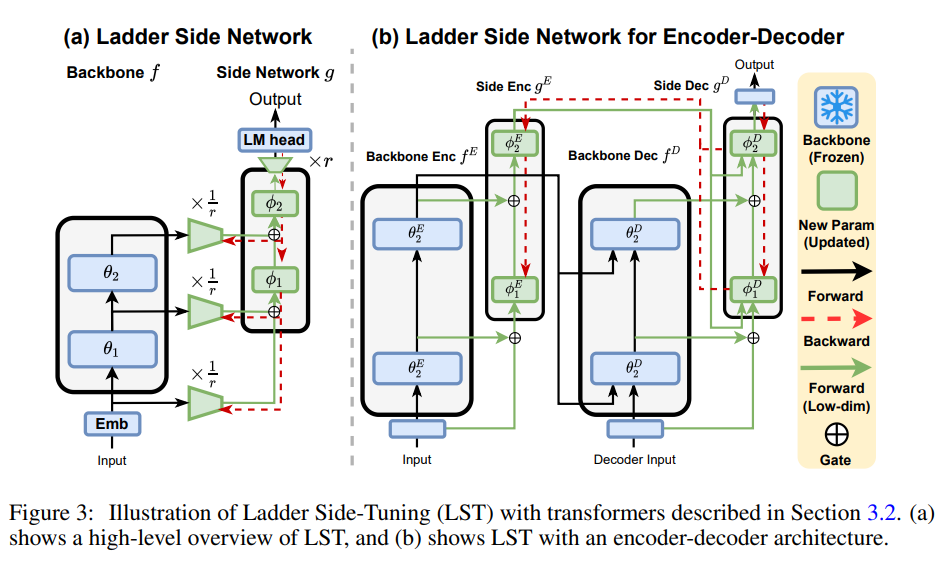
LST在原有大模型的基础上搭建了一个“旁支”(梯子),将大模型的部分层输出作为旁枝模型的输入,所有的训练参数尽在旁枝模型中。由于大模型仅提供输入,因此反向传播不会经过大模型,这样反向传播的复杂度取决于旁枝模型的规模,从而提高了训练的效率。
LST不仅可以在BERT这样的Encoder-only结构中使用,同样也可以在Encoder-Decoder结构中使用,如下图所示: