OpenAI o1 技术整理
对OpenAI o1可能用到的技术进行整理。
如何让模型学会自我思考
主要是如下两篇论文中的内容:
- Let's Verify Step by Step
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
首先来看o1技术报告中的下图:
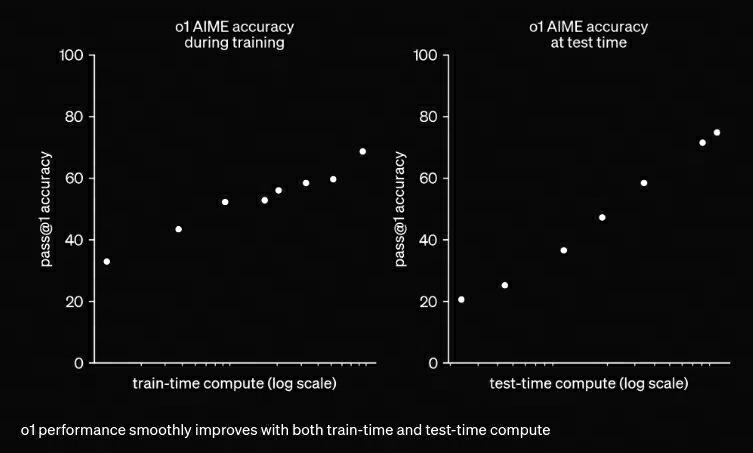
其中包含了train-time compute和test-time compute。
曾经,为了提升模型的逻辑推理能力,我们把算力都花在pretrain阶段,由此诞生了Pretrain
scaling law,对应上图中的train-time compute。
而o1证明,算力如果花在inference上,模型的推理能力将得到更大提升,也就是存在一个Inferece
scaling law,对应上图中的test-time compute。
把算力用在inference阶段,分为两种情况:
- 优化推理输入
- 优化推理输出
优化推理输入
这个方法大家应该非常熟悉了。其使用的就是CoT技术,如下图所示:
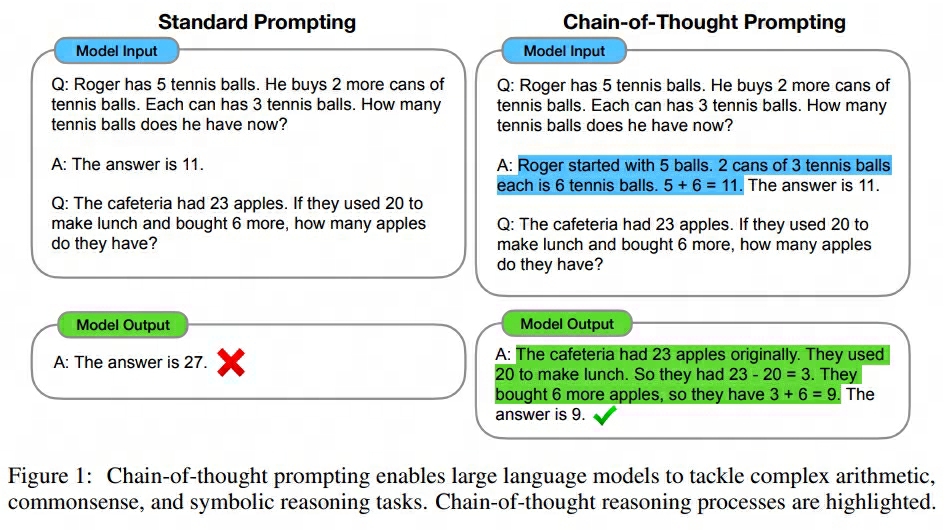
你的prompt给的越细节,你的多轮引导给的越多,模型或许就能产出更好的结果。而更多的token意味着推理阶段需要花费更多的算力,所以这就是我们所说的【把算力花在推理阶段上可以提升模型效果】的具体内容之一。
CoT的更多细节可以参考Chain-of-Thought Prompting Elicits Reasoning in Large Language Models这篇论文。
优化推理输出
可是,优化推理输入的方法还是不够直接。难道对于每一个问题,我需要精心设计prompt,或者手动诱导模型think step by step才行。所以能不能让模型吃下一个问题后,自动化地去做CoT的过程呢?
也就是说,现在我们希望模型在吃下一个问题后,能自主产生以下输出:
\(question \rightarrow attempt_1 \rightarrow attempt_2 \rightarrow attempt_3 \rightarrow ... \rightarrow attempt_i \rightarrow answer\)
先来看看Let's Verify Step by Step这篇论文的做法:
用一个已经pretrain好的大模型来生成符合如上格式的数据。
这里的大模型论文中使用的是GPT(large scale中使用了GPT-4),我们需要通过输入prompt+few-shot的方式引导模型从“只产生结果”变成“同时产生中间步骤和结果”,此时只关注是否产出了中间结果,而不关注中间结果的质量。论文中还将生成模型在产生的Cot数据中微调了一个epoch,使其更好的生成符合格式的数据。
将上述符合格式的数据打标并训练出奖励模型。
这里分为两种方式:
Outcome-supervision Reward Model(ORM)
该方式只使用最后答案的正确与否作为反馈信号,将思维链最后得到的答案是否正确作为label训练奖励模型。由于作者这里使用的是数学领域的数据集进行微调训练,这些数据都是提供了最终标准答案的,因此是天然的有监督数据,不需要人工参与标注。这种方式的缺点是会引入错误数据,即结果正确但中间步骤错误的数据会被当作positive数据训练奖励模型。
Process-supervision Reward Model(PRM)
该方式将每一个推理步骤的正确与否作为反馈信号,将思维链每一个步骤正确与否作为label训练奖励模型。这些步骤是无法自动获取到标注结果的,所以需要人工参与标注。标注示例如下所示:
在数据标注过程中,作者还使用了Active Learning的技巧。
由于人工标注成本较高,如果标注一些低价值的数据是十分浪费的,所以作者倾向与让人工标注一些高价值数据。
这里的高价值指的是PRM模型判断得分很高,但最终答案却错了的数据。这些数据对训练PRM可以起到更为关键的作用。
同时,在标注的过程中,PRM是会实时用最新的数据重新训练得到更新的,这样人工标注的数据就一直是训练PRM的高价值数据。通过上图中的方法,OpenAI获取并公开了PRM800K数据集,其中包含了12,000个数学问题的75,000个解决方案,共计800,000个步骤级别的标签。
最终得到的Process-supervision Reward Model可对思维链中每个步骤进行打分,如下所示:

通过强化学习方法,结合奖励模型的结果,微调生成大模型。
通过上述各种方案得到的结果如下:
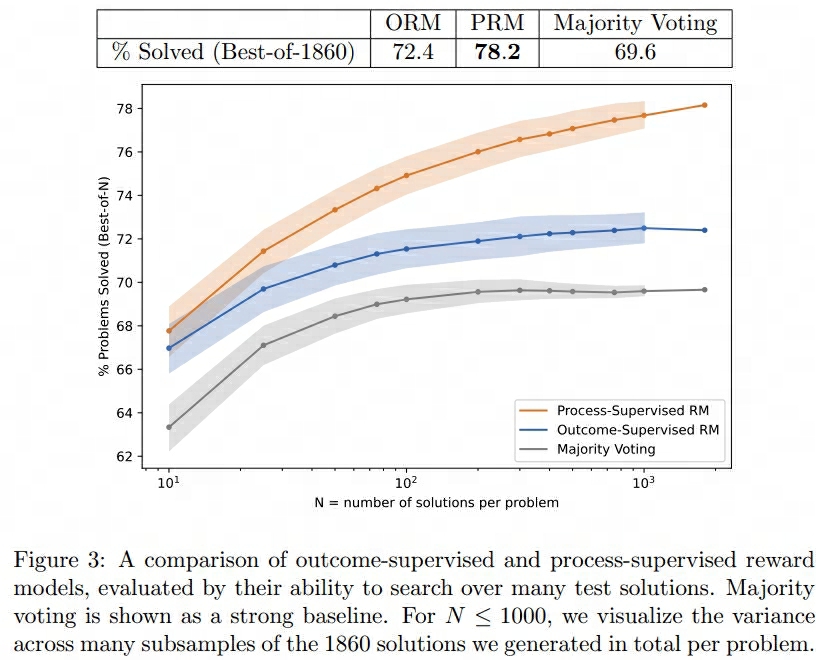
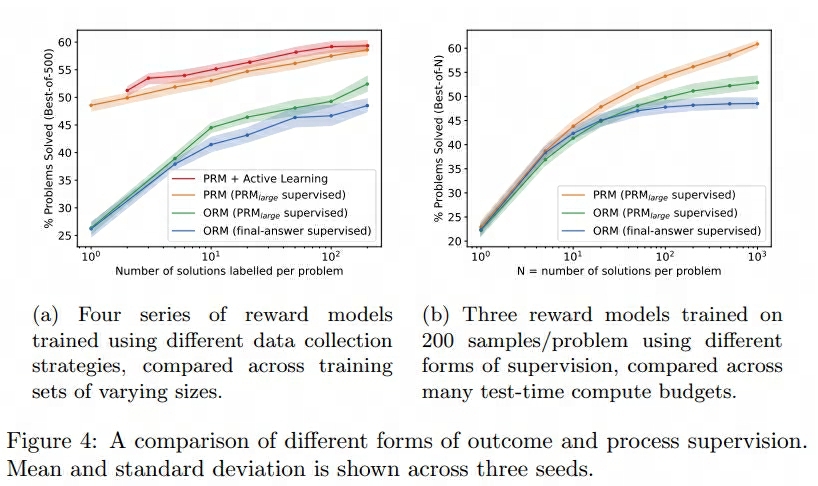
然后再来看看Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters这篇论文的做法:
论文中中提出了两种方案优化推理输出:
一种方案是通过SFT训练,改变生成模型的输出分布,使模型生成即符合格式要求,又符合质量需求的数据。问题在于如何才能使用最少的成本,生成高质量的涵盖中间思考步骤的sft数据?
- 先对模型做格式微调,使其能够产出“中间结果 + 答案”。这一步只负责格式,不负责质量。
- 由于每个attempt中都包含了答案,答案是有标签的,所以我们可以知道哪些attempt给出了正确答案。
- 我们希望为每个正确attempt匹配上若干错误attempt,作为一条训练数据。也就是我们的训练数据是“问题 + 若干错误attempt+正确attempt”的形式,这一步是让模型模拟人类思考的模式,从步步错误的attempt中推出正确的attemp。
最终得到的数据如下图:

在构造attemp链训练数据时,论文中也有一些细节。
如要对一个正确回答匹配\(x\)个错误回答时,会根据编辑距离先从所有的错误回答中找到和正确回答最相似的错误回答。
然后再从剩下的不正确的回答中,随机采样\(x-1\)条。 最终构造的训练数据为:
\(问题 \rightarrow 随机不正确的x-1条回答 \rightarrow 最相似的不正确回答 \rightarrow 正确回答\)。
这样模型可以学得更好。只通过答案判断attemp的正确与否不够准确,为了取得更好的效果,实际上论文中依然会配合PRM和ORM对中间步骤再做评估,更有利于选择尽可能正确的attempt。如下图所示:
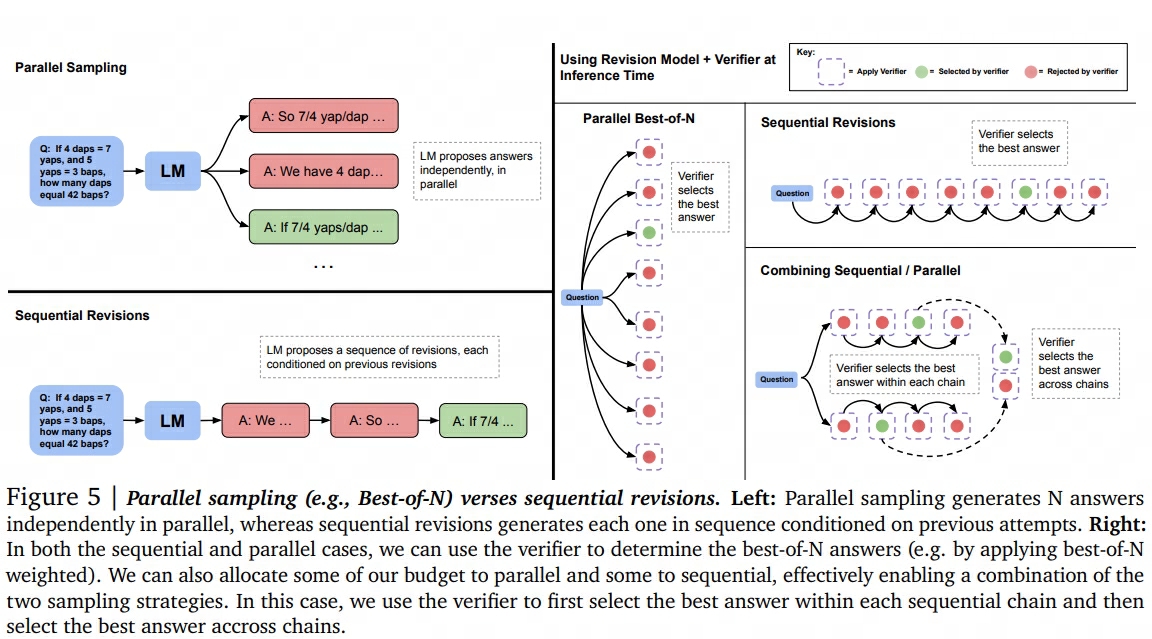
另一种方案是利用PRM指引搜索。
- 先对模型做格式微调,使其能够产出“中间结果 + 答案”。这一步只负责格式,不负责质量。
- 现在,模型已经能在生成结果里产出“思考步骤”数据了。我们需要训练一个能够评估这些steps的奖励模型,也就是PRM。这一步和Let's Verify Step by Step中训练PRM的过程一致。
- 到这一步为止,我们已经有以下模型:
- 一个能按照格式,产出中间思考步骤的模型(generator),但中间思考步骤质量得不到保证。
- 一个能对中间思考步骤进行评估的奖励模型PRM。
而现在我们想做的事情是:如何在不对generator继续做任何训练的情况下,使用PRM来引导generator搜索出最佳的“steps + answer”。论文中给出了3种常用的搜索方案,如下图所示:
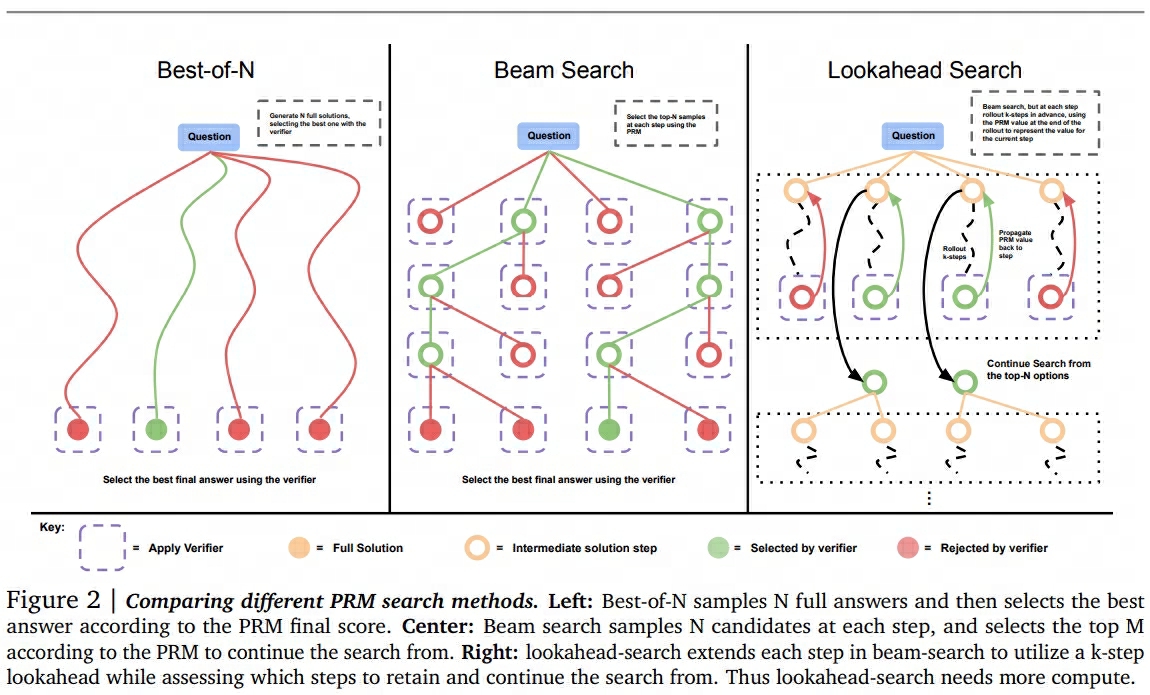
其中:
- Best-of-N对一个问题采样N个samples,然后调用PRM对这N个sample进行整体打分,选取整体得分最高的那组steps + answer作为输出。
- Beam search在每个step通过PRM筛选出分数最高的top M个结果继续生成。
- Lookahead search对每一步做筛选时,都会先“向前看K步”,用K步后的收益去评估当前步骤的结果。(如评估当前step时,让它继续往下生成K个step,然后将最后一个steps们送进PRM进行打分,并筛选出分数最高的top M个结果。)
使用PRM对数据整体进行打分的方式有:
- 连乘式(prod):将所有steps的得分相乘,用于表示整体的分数。
- 最小式(min):取所有steps中最小的得分作为整体得分。
- 最后一步式(last step):取last step的得分,反映出整体得分。
prod和min是openAI在Let's Verify Step by Step中探索的方法,last step则是deepmind在Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters中使用的方法。
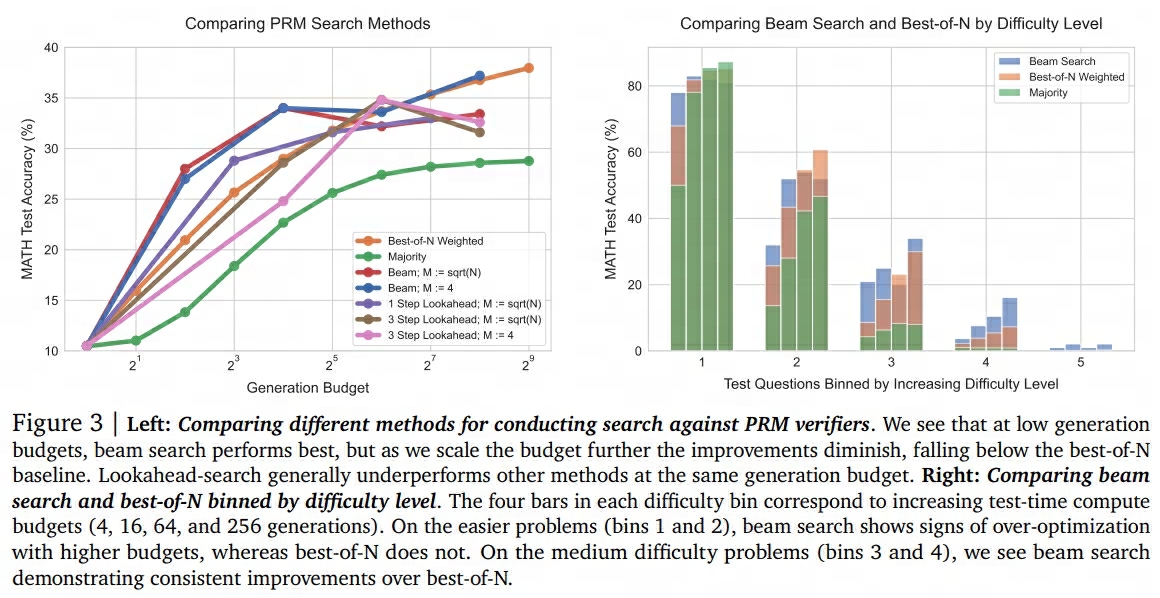
不同搜索方法的对比结果如下图所示:
如何让模型学会自我纠正
该部分相关的论文如下: