STaR和Quiet-STaR
论文地址:
STaR
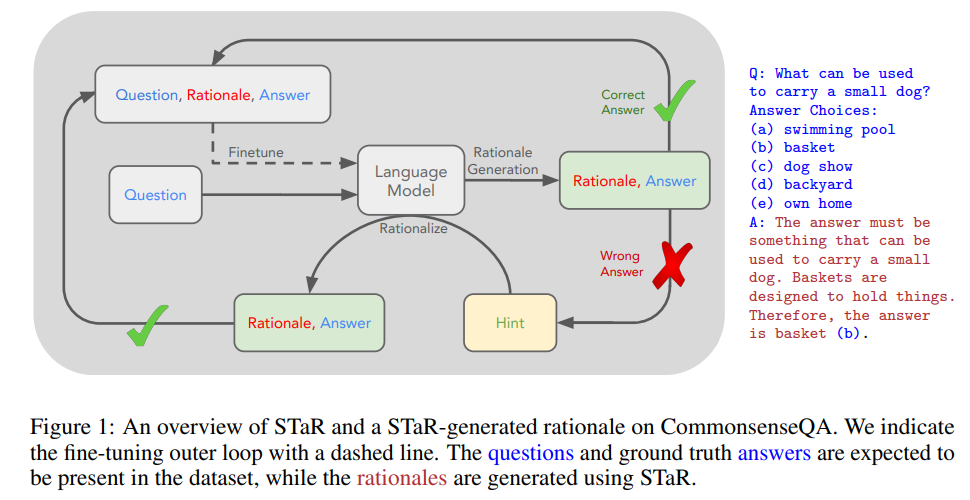
STaR分为两个部分,分别为STaR Without Rationalization和Rationalization,如下所示:

数据生成:人工生成一些推理+答案的内容,然后通过In-Context-Learning的方法来让模型生成推理过程+答案。答案过滤v1:只保留答案正确的推理过程,默认答案正确的推理过程是好的推理过程。答案过滤v2:对于答案错误的数据,给出问题+正确答案,重新让模型生成推理过程。- 用步骤2得到的数据微调模型,得到更好的生成模型。
- 用步骤3得到的数据微调模型,得到更好的生成模型。
- 重复1~5步骤,不断改进模型的推理能力。
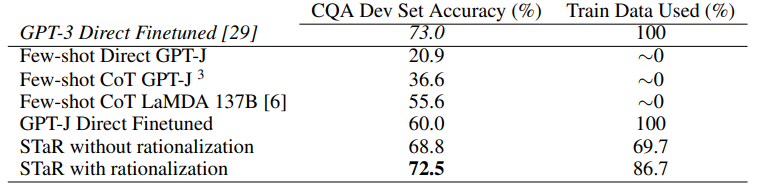
STaR结果如下所示:
Quiet-STaR
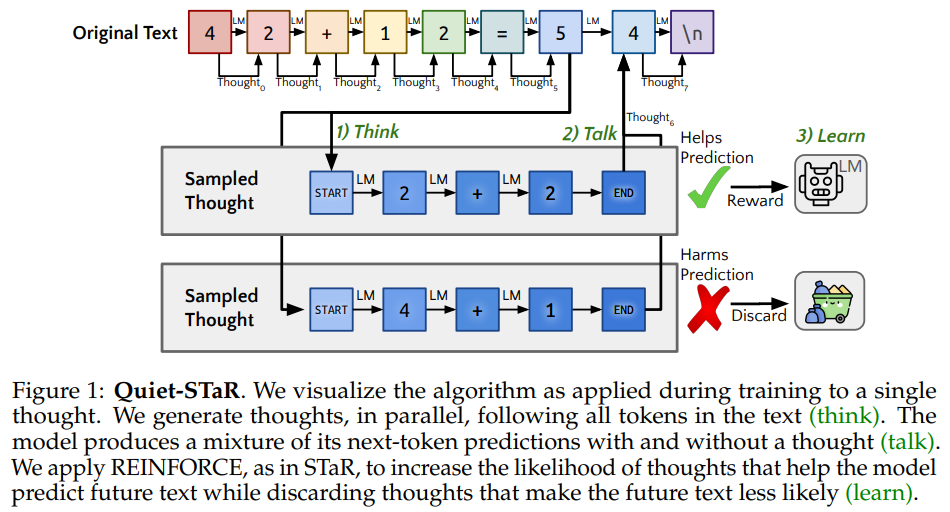
在Quiet-STaR中,语言模型学习在每个token生成时生成思考步骤(thoughts),以解释未来文本,从而改善其预测。如下图所示:
其优化函数为:
\[\theta^{*} = \arg \mathop{max}\limits_{\theta}E_x[logp_{\theta}(x_{i:n}|x_{0:i},rationale_{\theta}(x_{0:i}))]\]
意思是模型不仅要根据之前的输入token \(x_{0:i}\)来预测后续token \(x_{i:n}\),还要生成一个中间的推理过程\(rationale_{\theta}\),用以提升对后续序列的预测能力。
Quiet-STaR模型有三个主要步骤:
并行思考步骤生成
对于输入序列中的\(n\)个token \(x_i\),并行生成长度为\(t\)的\(r\)个推理(或思考步骤)\(c_i=(c_{i1},c_{i2},...,c_{it})\),最终生成\(n \times r\)个推理候选。
混合两种形式的推理
通过每个推理生成后的隐藏状态,训练一个“混合头”(shallow
MLP),产生权重,决定有思考步骤的下一个词的logits与无思考步骤的logits之间如何融合。
优化推理生成
通过优化思考起始/结束token,来使模型的训练更容易。
使用非短视评分方法,更充分的考虑推理链对后续预测的影响。
采用教师强制技巧(teacher-forcing
trick),解决模型熵太高导致文本质量下降的问题。
并行思考步骤生成
因为本文基本思想是在每个token后都去生成思考步骤,所以如果按顺序对每个token进行生成不可避免地会产生多次前向传播,这对于长序列来说在时间上的花费是让人难以接受的。
所以为了高效的实现并行思考步骤生成,本文提出了特殊的注意力掩码方法,并行生成每一个token处的思考步骤,如下图所示:
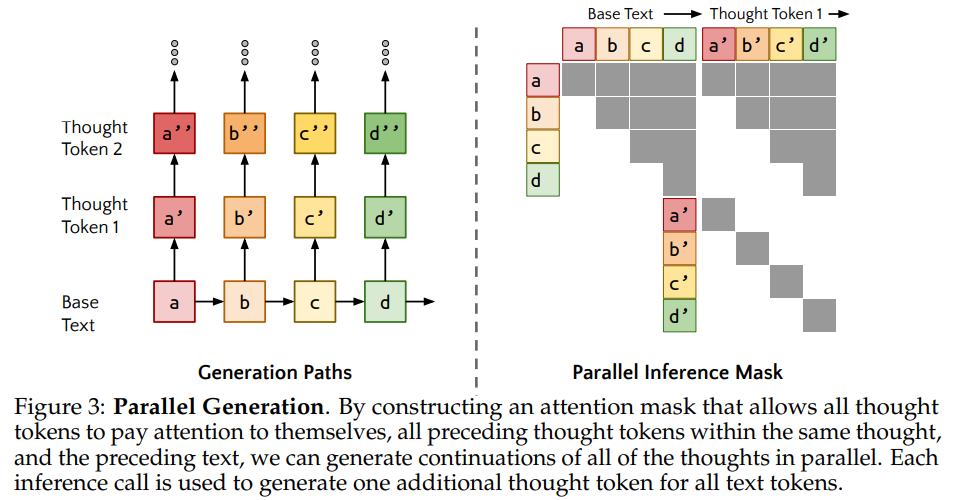
假设输入的Base Text是abcd,然后在并行生成Thought Token1时,a允许注意到a本身,b则是a,b,以此类推,去生成a',b',c',d'。在生成Thought Token2时a'允许注意到a和a',去生成a'',b'允许注意到a,b,b'去生成b''。依次类推生成c''和d''。因此注意力掩码就形成了如上图所示的上三角+对角注意力掩码,生成后续Thought Token的过程其实就是在继承上次的掩码的同时,增加一个对角注意力掩码。
混合两种形式的推理
在使用预训练模型时,由于预训练模型并没有被设计来处理“思考”(thoughts)这种额外的信息,刚开始生成的推理会与模型的原始数据分布不一致(out of distribution)。这会对语言建模的性能产生负面影响。简单来说,预训练模型并不习惯处理“思维过程”的信息,因此需要一个平滑的过渡来适应这种新信息。
为了平滑引入推理的过渡,作者提出了一种插值方法,在语言模型的预测中引入“有思考步骤”与“无思考步骤”的预测混合。也就是说,模型需要根据推理信息来调整其预测的权重,平衡“有思考步骤”和“无思考步骤”的结果。
本文使用一个浅层的MLP来生成每个token的权重。这个 MLP 的输出是一个标量(scalar),表示每个token的混合权重,权重越大,模型越倾向于使用带有思考步骤的预测结果。
思考过程thoughts是被两个特殊token包围的,分别为思考开始token
<start-of-thought>,和思考结束token
<end-of-thought>。
MLP的输入分为两个部分:
- token本身的隐藏状态(代表无思考步骤的结果)
<end-of-thought>token的隐藏状态(代表有思考步骤的结果)。
实际上混合头的输入是一个向量,这个向量的大小是带有思考过程的预测和不带思考过程的预测拼接在一起得到的。 混合头使用了一个三层的 MLP,作为计算权重的核心部分。MLP 的每一层使用了 ReLU 激活函数,最终输出一个标量用于对两类logits的加权。
优化推理生成
优化推理开始和结束token
优化这些token的表示非常重要,尤其是<start-of-thought>
token,因为它会影响模型如何生成思考过程。作者选择将思考开始和结束的嵌入初始化为类似于文本中的破折号
——,这种符号在文本数据中通常表示一个停顿或思考的开始,借此利用语言模型已经具备的先验知识,使模型在初始化时有更好的特征表示。
为了更快地优化这些特殊符号,作者给这些token增加了一个超参数权重。简单来说,模型在每次训练中调整这些token的权重时,会给它们的梯度施加一个额外的权重,从而加速它们的学习。
非短视评分和教师强制
目前模型的奖励来自于是否有助于预测下一个token,但作者认为模型的奖励机制应该更多地依赖后续的语义内容,而不是仅仅依赖于思维之后生成的下一个具体token,因此提出了非短视评分和教师强制的方法。如下图所示:
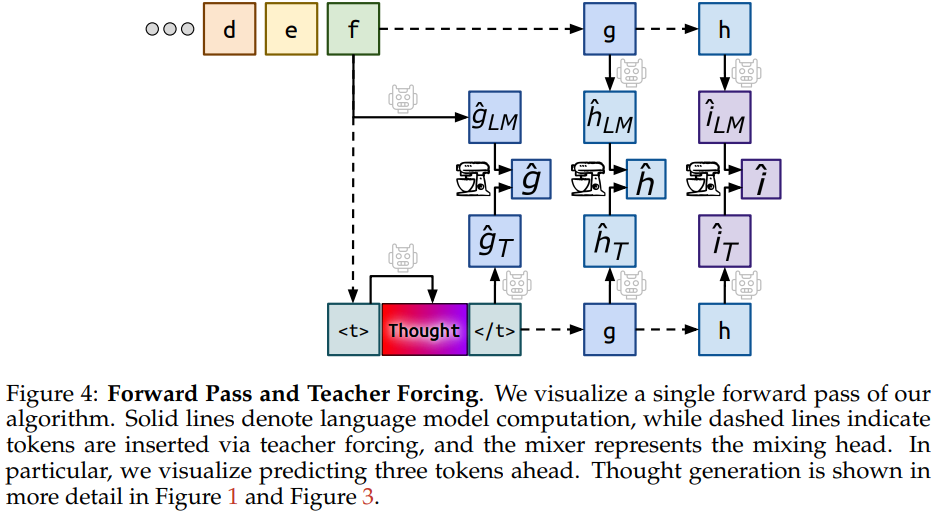
非短视评分
对于\(f\)的推理链更新,会设置一个向后观察几个token的超参数,如图中设定的超参是3。然后在计算损失函数更新参数时,会将这些token的结果一起计算,作为当前步骤的奖励。
教师强制
如图中虚线部分,模型的输入不使用预测得到的token(\(\hat{g}、\hat{h}),而是强制使用正确的输入token(\)g、h$)。这样的话就保证了每一次预测下一个token时,模型前面传入的token都是正确的。不会出现语言模型熵太高导致文本质量下降的问题。
这里是为了优化\(f\)的推理链,所以在预测第二个token \(h\)的时候,使用的仍然是token \(f\)的thoughs,而不是token \(g\)的thoughs(在inference阶段时预测token \(h\)使用的是token \(g\)的thoughs)。
上图可直观的看到混合推理的过程,无思考步骤的推理为上半部分的\(g\)和\(h\),有思考步骤的推理为下半部分的\(g\)和\(h\)。两者通过一个MLP进行融合。