ModernBERT介绍
ModernBERT 是一个全新的模型系列,在速度和准确性两个维度上全面超越了 BERT 及其后继模型。这个新模型整合了近年来大语言模型(LLMs)研究中的数十项技术进展,并将这些创新应用到 BERT 风格的模型中。
论文地址:
论文代码:
- https://github.com/AnswerDotAI/ModernBERT
- https://huggingface.co/collections/answerdotai/modernbert-67627ad707a4acbf33c41deb
ModernBERT 的技术创新
ModernBERT主要从三个方面着手改进传统的BERT模型:
- Transformer 架构的现代化革新
- 计算效率的系统性优化
- 训练数据的规模化和多样化
Transformer 架构的现代化革新
近年来,大模型相关技术有了长足的进步。ModernBERT用现代化的等效组件替换了传统的 BERT 式构建模块:
- 采用"旋转位置编码"(RoPE)取代传统位置编码:这一改进显著提升了模型对词序关系的理解能力,同时为序列长度的扩展提供了技术基础。
- 将传统的 MLP 层升级为 GeGLU 层,对原始 BERT 的 GeLU 激活函数进行了优化。
- 通过消除冗余偏置项精简架构,实现了参数预算的更高效利用。
- 在嵌入层后增加规范化层,提升了训练过程的稳定性。
计算效率的系统性优化
ModernBERT 的效率优化策略主要包含三个核心组件:交替注意力机制用于提升处理效率,去填充和序列打包技术用于减少计算资源浪费,以及硬件感知的模型设计用于优化硬件利用率。
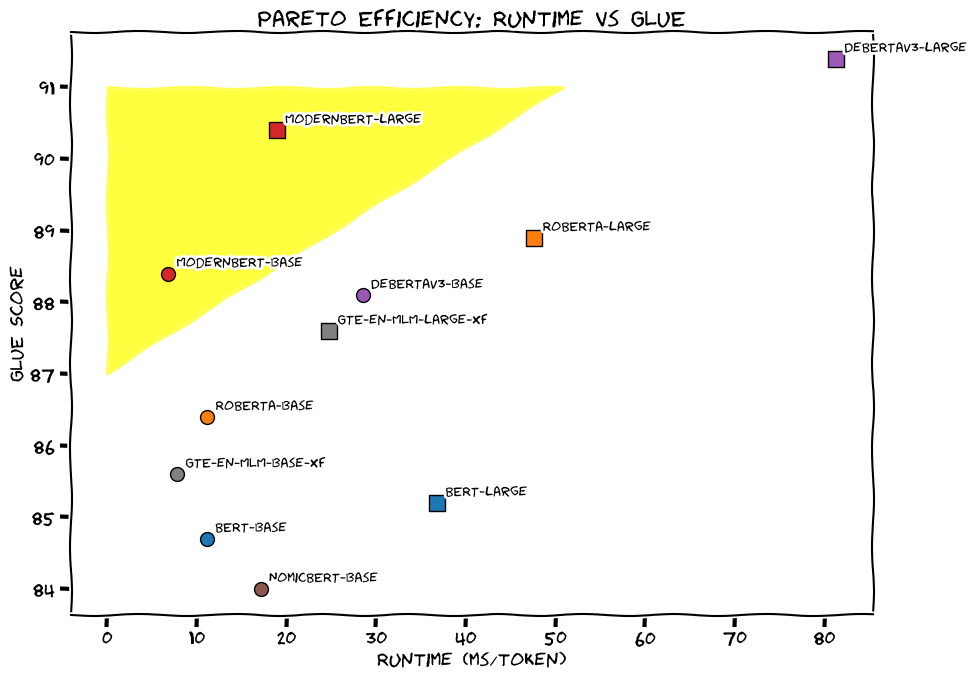
Global and Local Attention
ModernBERT 的一项关键技术创新是引入了交替注意力机制,这与传统的全局注意力方案有着本质的区别。这种机制的特点是在模型的每三层中只有一层执行完整的全局注意力计算(全局注意力),而其他层采用滑动窗口策略,每个token仅关注其最近的 128 个token(局部注意力)。考虑到注意力机制的计算复杂度会随token数量的增加而急剧上升,这种设计使得 ModernBERT 能够比现有模型更高效地处理长序列输入。
其实现架构如图所示:
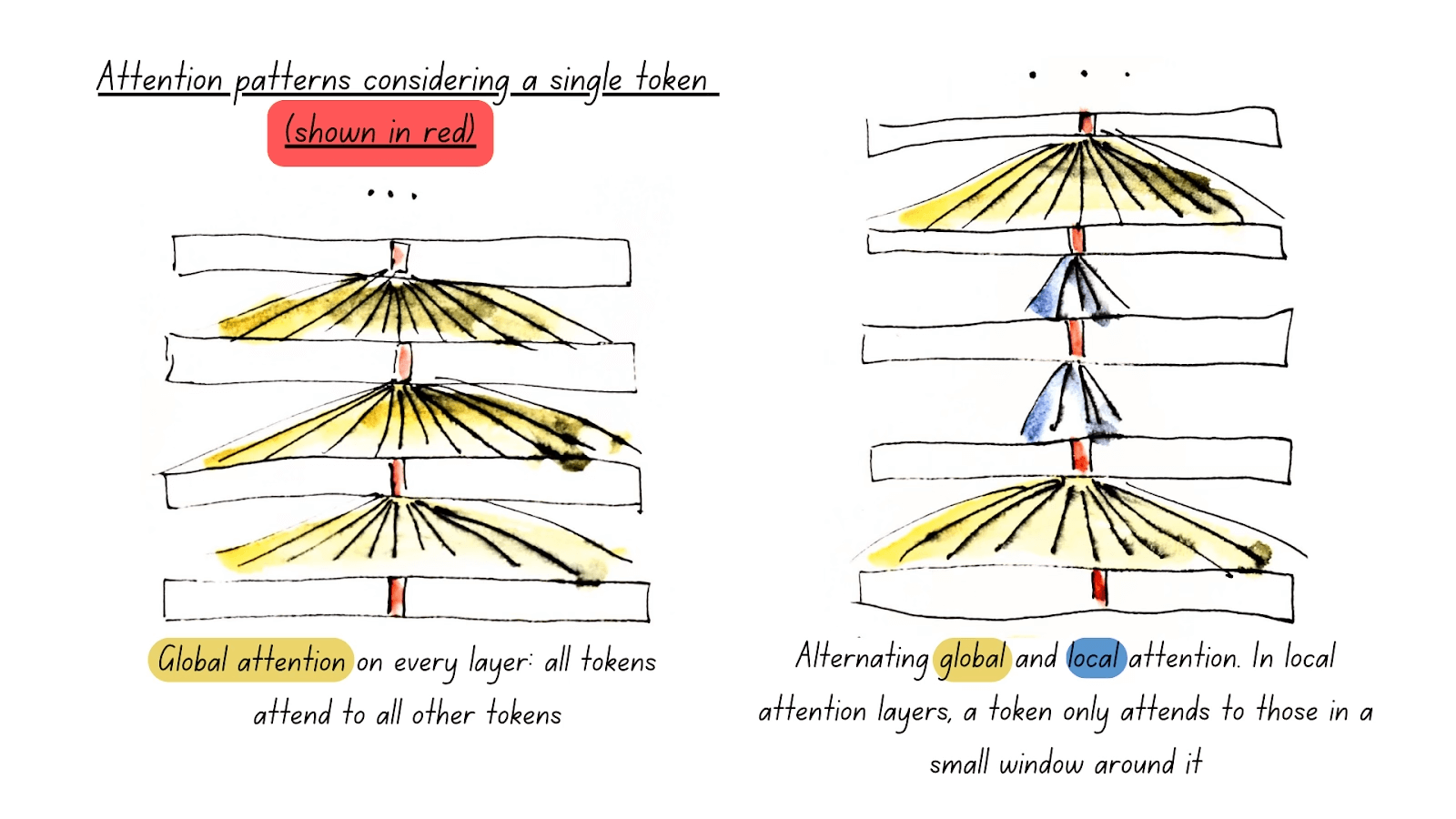
Unpadding and Sequence Packing
另一个提升 ModernBERT 计算效率的核心技术是去填充和序列打包机制。
在传统的编码器模型中,为了实现批处理的并行计算,所有输入序列都需要保持相同的长度。这通常通过填充技术实现:将所有序列补齐到最长序列的长度,补充的部分使用无意义的填充token。这种方法虽然简单直接,但存在明显的计算资源浪费,因为模型需要处理大量不携带任何语义信息的填充token。
这一问题的优化过程如图所示:
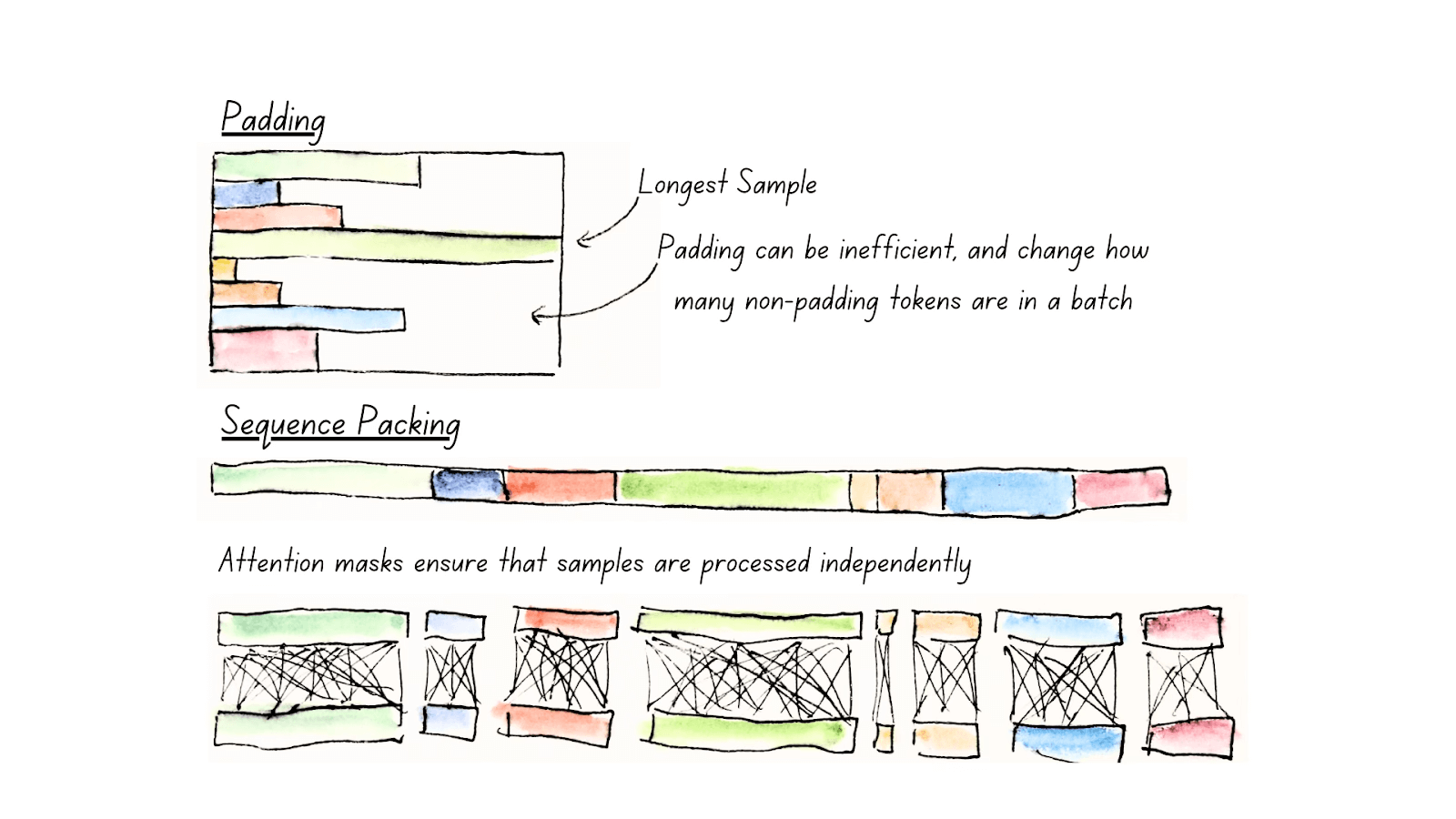
去填充技术完全移除填充标记,将实际内容重组为批量大小为一的小批次,从而避免了冗余计算。
为进一步提升预训练效率,将去填充技术与序列打包机制相结合。考虑到 GPU 的并行计算优势,应当充分利用每次模型前向传播的计算资源。所以ModernBERT实现了一个贪婪算法,将独立序列组合成接近模型最大输入长度的统一序列。
硬件感知的模型设计
ModernBERT 效率优化的第三个关键维度是硬件感知的设计理念。
设计试图平衡两个来自先前研究的重要发现:
- 深度与宽度的权衡:研究表明,在相同参数规模下,具有较窄层的深层模型通常比具有较少但较宽层的浅层模型表现更好。但这种设计存在一个技术权衡:模型越深,其并行化的难度就越大,从而影响处理速度。
- 硬件适配性:模型维度需要与目标 GPU 架构保持良好的对齐,不同的 GPU 平台会带来不同的优化约束。虽然没有一种通用的优化方案能够使模型在所有 GPU 平台上都达到最佳性能,但可以参考优秀的设计指南,如《与硬件共同设计模型架构的案例》,其中详细阐述了针对特定 GPU 优化模型架构的方法。
基于这些见解,ModernBERT开发了一种启发式方法,将单一 GPU 的优化策略扩展到多个 GPU 平台,同时满足一系列预设约束。具体而言,优化约束包括:
- 确定目标 GPU 平台:主流推理硬件(RTX 3090/4090、A10、T4、L4)
- 设定模型规模范围:ModernBERT-Base 为 1.3-1.5 亿参数,ModernBERT-Large 为 3.5-4.2 亿参数
- 保持嵌入维度与原始 BERT 一致:基础版 768,大型版 1024,以确保最大程度的向后兼容性
- 制定适用于所有目标 GPU 的统一性能标准
在此基础上,还通过受约束的网格搜索方法,系统地探索了不同的模型配置,包括层数和层宽的各种组合。在识别出最具潜力的架构配置后,通过实际 GPU 性能测试验证了启发式方法的有效性,最终确定了最优的模型设计方案。
训练方法的创新
ModernBERT 采用了更加多元化的训练数据策略,整合了来自网络文档、程序代码和学术论文等多种英语文本源。训练规模达到2 万亿token,其中绝大部分是独特的内容,而不是像传统编码器那样对相同内容进行 20-40 次重复训练。
训练过程
在保留原始 BERT 训练方法核心的同时,根据后续研究成果进行了若干优化:移除了收益不明显的下一句预测目标,同时将掩码比率从 15% 提升至 30%。
模型采用三阶段训练策略。
- 首个阶段在序列长度为 1024 的条件下处理 1.7 万亿token;
- 第二阶段进入长上下文适应训练,在序列长度扩展到 8192 的情况下处理 2500 亿token,通过调整批次大小来维持每批次的总token数相对稳定;
- 最后阶段基于 ProLong 提出的长上下文扩展最优混合原则,对 500 亿个特选token进行退火训练。
这种三阶段训练方法确保了模型在各种应用场景中的稳定表现:它不仅在长文本处理任务上具有竞争力,同时保持了对短文本的高效处理能力。
训练技巧
- 考虑到训练初期主要是在更新随机初始化的权重,实现了批次大小预热机制 —— 以较小的批次规模开始训练,使相同数量的token能够更频繁地参与权重更新,随后逐步增加到目标批次大小。这种方法显著加速了模型在语言基础理解阶段的训练过程。
- 为大型模型设计了基于平铺的权重初始化方案。将 ModernBERT-base 的权重通过平铺方式扩展到 ModernBERT-large 比随机初始化表现更好。这种方法与批次大小预热机制配合使用,进一步加速了初始训练过程。
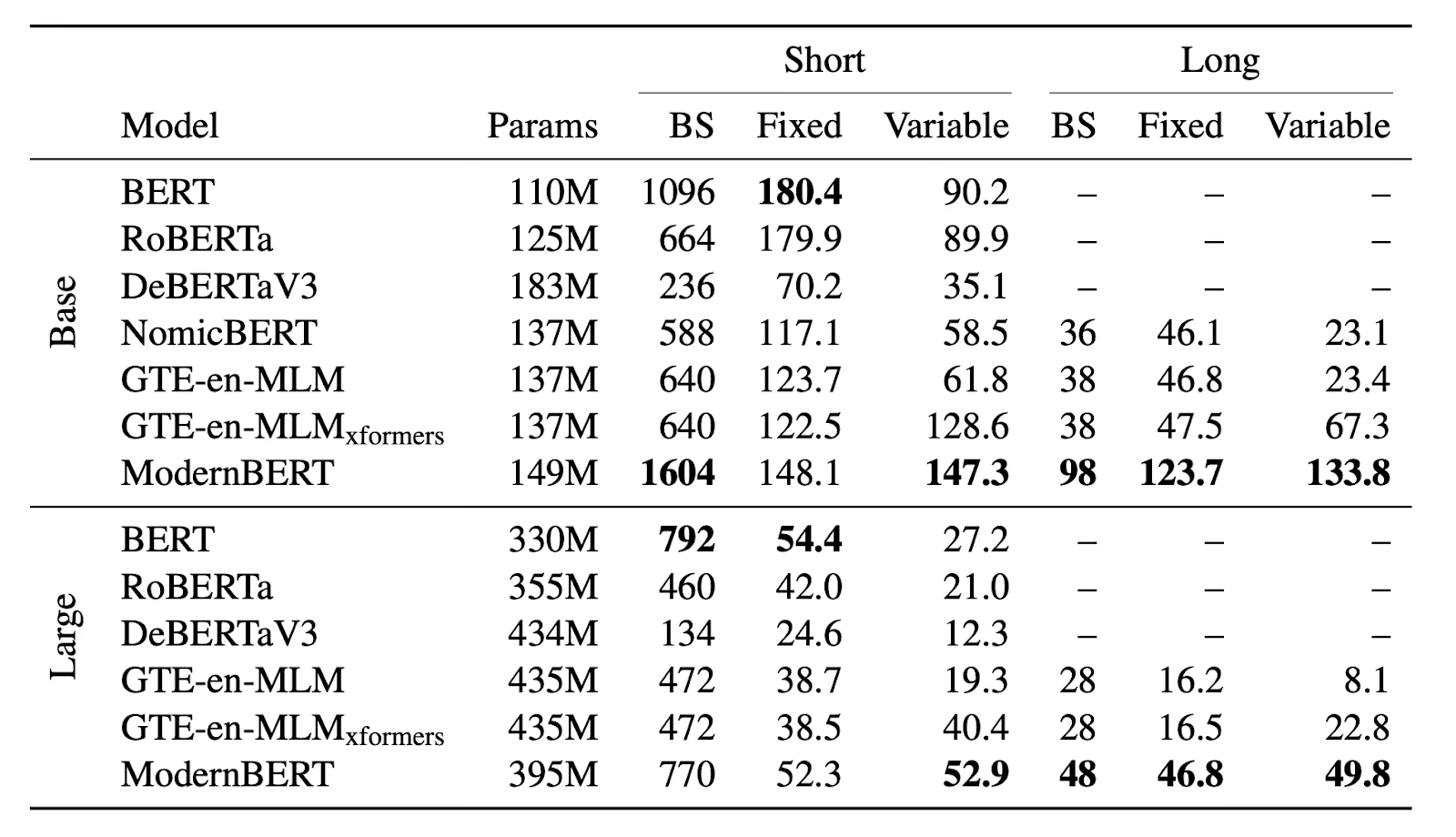
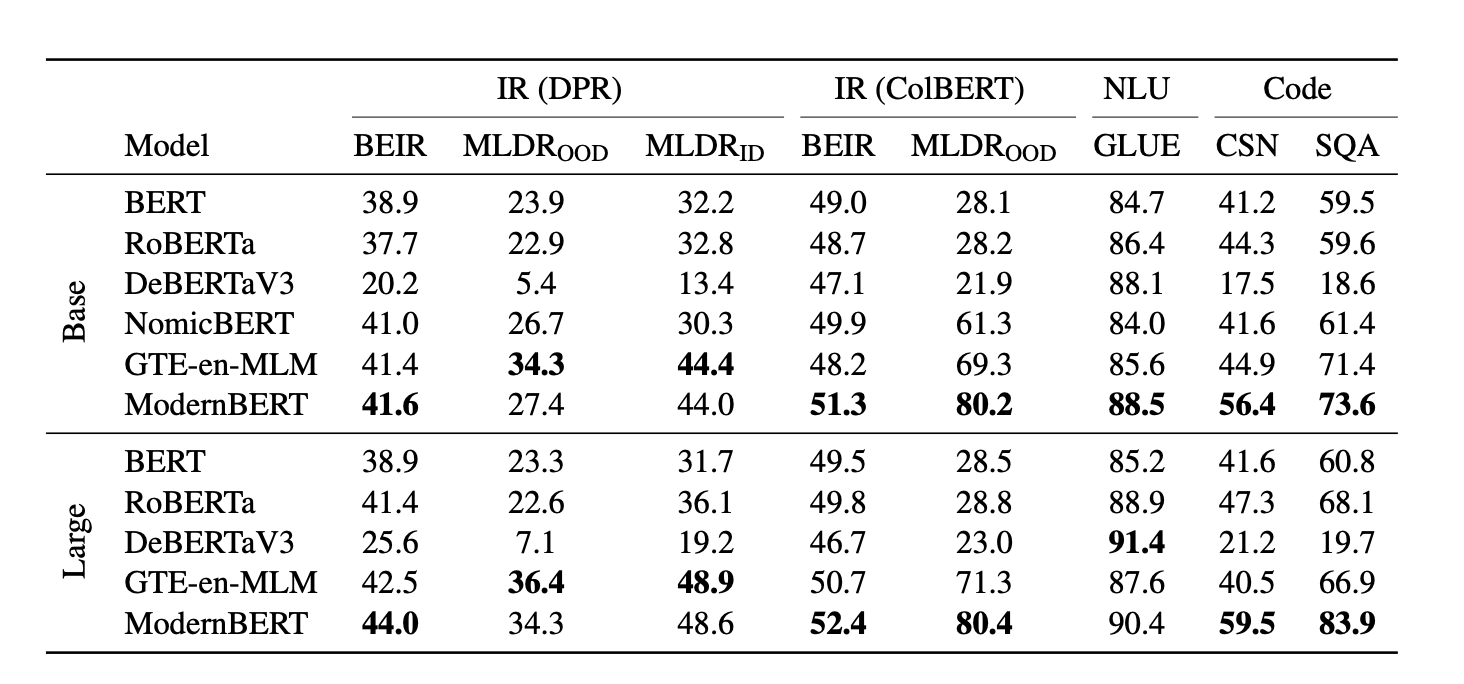
Performance
下图展示了 ModernBERT 与其他模型在标准学术基准测试中的准确率对比:
下图展示了 ModernBERT 与其他模型在 NVIDIA RTX 4090
上的内存使用(最大批量大小,BS)和推理性能(每秒千token数)对比: