DeepSeekMoE详解
论文地址:
论文代码:
这篇文章来说DeepSeekMoE算法的原理。
基础知识
标准transformer语言模型构造由\(L\)层的标准transformer块堆叠构成,每个块表示如下:
\[ \begin{align} u_{1:T}^l &= SelfAtt(h_{1:T}^{l-1}) + h_{1:T}^{l-1} \\ h_t^l &= FFN(u_t^l) + u_t^l \end{align} \]
其中\(T\)表示序列长度,Self-Att(·) 表示自注意力模块,FFN(·) 表示前馈网络。
传统的MoE网络将transformer语言模型中的FFN层替换成MoE层,如下所示:
\[ \begin{align} h_t^l &= \sum_{i=1}^N(g_{i,t}FFN_i(u_t^l)) + u_t^l, \\ g_{i,t} &= \begin{cases} s_{i,t}, s_{i,t} \in Topk(\{s_{j,t}|1 \leq j \leq N\}, K), \\ 0, otherwise, \end{cases} \\ s_{i,t} &= Softmax_i({u_t^l}^{\top}e_i^l), \end{align} \]
其中\(N\)表示专家总数,\(FFN_i(·)\)是第\(i\)个专家的\(FFN\),\(g_{i,t}\)表示第\(i\)个专家的门控值,\(s_{i,t}\)表示token到专家的亲和度。
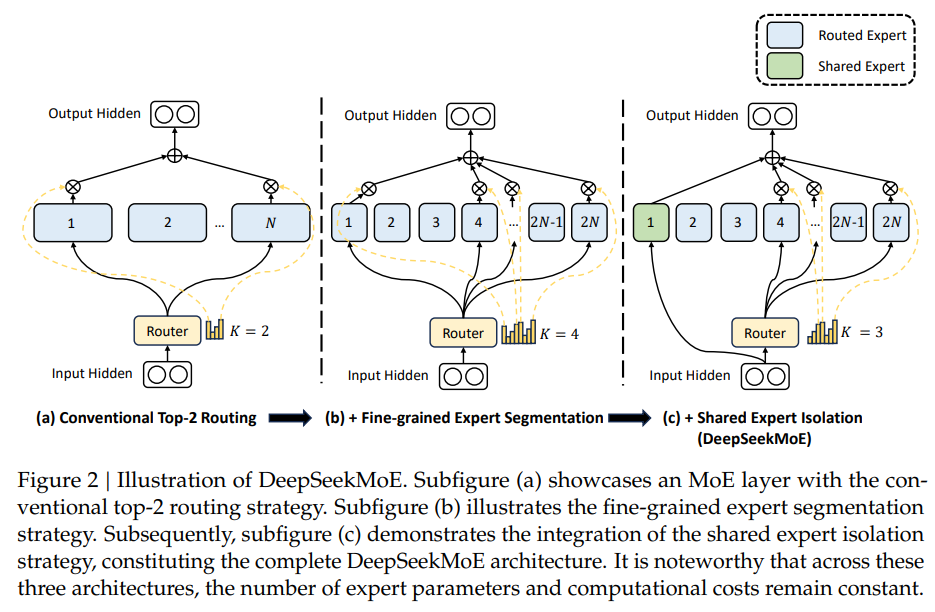
传统的MoE架构将transformer中的前馈网络(FFNs)替换为MoE层,每个MoE层由多个与标准FFN结构相同的专家组成,每个token被分配给一个或两个专家。现有的MoE架构可能遭受知识混合(Knowledge Hybridity)和知识冗余(Knowledge Redundancy)的问题,这限制了专家的专业化。
- 知识混合: 现有MoE实践通常使用有限数量的专家(如8或16),因此分配给特定专家的tokens可能覆盖多种知识,导致专家在其参数中聚合不同类型的知识,难以同时利用。
- 知识冗余: 分配给不同专家的tokens可能需要共同的知识,导致多个专家在各自的参数中收敛获取共享知识,从而引起专家参数的冗余。
DeepSeekMoE提出了两点改进:
Fine-grained Expert Segmentation:在保持参数数量不变的同时,通过细分FFN的中间隐藏维度,将专家分割成更细的粒度。相应地,在保持恒定的计算成本下,激活更多细粒度的专家,以实现更灵活、适应性更强的激活专家组合。专家细分允许将不同的知识被更精确地学习以及被更细致地分配到不同的专家,每个专家都将保持更高水平的专业化。此外,增加专家激活的灵活性也有助于更准确和有针对性的知识获取。Shared Expert Isolation:隔离某些专家作为始终激活的共享专家,可以捕获和整合不同上下文中的共同知识。通过将共同知识压缩到这些共享专家中,可以减轻其他路由专家中的冗余。这可以提高参数效率,并确保每个路由专家通过专注于独特方面而保持专业化。
Fine-grained Expert Segmentation
Fine-grained Expert Segmentation实现细节如下:
- 将专家数量变为原来的\(m\)倍,即专家数量为\(mN\)。
- 为了保证参数数量不变,将每个FFN的intermediate hidden dimension变为原来的\(\frac{1}{m}\)。
- 由于每个专家都变小了(变为\(\frac{1}{m}\)),所以将激活的专家数也变为原来的\(m\)倍,即激活的专家数量为\(mK\)。
则DeepSeekMoE可以表示为如下式子:
\[ \begin{align} h_t^l &= \sum_{i=1}^{mN}(g_{i,t}FFN_i(u_t^l)) + u_t^l, \\ g_{i,t} &= \begin{cases} s_{i,t}, s_{i,t} \in Topk(\{s_{j,t}|1 \leq j \leq mN\}, mK), \\ 0, otherwise, \end{cases} \\ s_{i,t} &= Softmax_i({u_t^l}^{\top}e_i^l), \end{align} \]
这样,当\(N=16\)时,传统的top-2路由策略可以产生\({16 \choose 2}=120\)种组合。而同样参数数量的DeepSeekMoE,取\(m=4\),则Fine-grained路由策略可以产生\({64 \choose 8}=4426165368\)种组合,灵活度大大增加。
Shared Expert Isolation
在传统的MoE路由策略中,分配给不同专家的tokens可能需要一些共同的知识或信息,这可能导致多个专家在其参数中收敛获取共享知识,从而导致专家参数的冗余。而通过专门用于捕获和整合不同上下文中的共同知识的共享专家,可以减轻其他路由专家之间的参数冗余。冗余的减少有助于创建一个更高效的参数模型并拥有更专业化的专家。
Shared Expert Isolation实现细节如下:
- 隔离出\(K_s\)个专家作为共享专家。不管路由模块如何,每个token都会被分配给这些共享专家。
- 非共享的激活的专家数量减少\(K_s\)个。
则带有共享专家的DeepSeekMoE可以表示为如下式子:
\[ \begin{align} h_t^l &= \sum_{i=1}^{K_s}FFN_i(u_t^l) + \sum_{i=K_s + 1}^{mN}(g_{i,t}FFN_i(u_t^l)) + u_t^l, \\ g_{i,t} &= \begin{cases} s_{i,t}, s_{i,t} \in Topk(\{s_{j,t}|K_s + 1 \leq j \leq mN\}, mK-K_s), \\ 0, otherwise, \end{cases} \\ s_{i,t} &= Softmax_i({u_t^l}^{\top}e_i^l), \end{align} \]
Load Balance Consideration
自动学习的路由策略可能导致负载不均衡,这主要表现为两个缺陷:
- 路由崩溃的风险(即模型总是只选择少数几个专家,阻止其他专家获得足够的训练)。
- 如果专家分布在多个设备上,设备间的负载不均衡可能加剧计算瓶颈。
为此,DeepSeekMoE增加了两个损失:
- 专家间平衡损失(Expert-Level Balance Loss): 为了减轻路由崩溃的风险,引入专家间平衡损失值。
- 设备间平衡损失(Device-Level Balance Loss): 为了减轻计算瓶颈,引入了设备级平衡损失值。
在DeepSeek-V3中,作者进一步提出了无辅助损失负载平衡的DeepSeekMoE。
针对专家负载不均衡的问题,为每个专家引入了一个偏置项\(b_i\),并将其加到的亲和力得分\(s_{i,t}\)上。如下式所示:
\[ \begin{align} g_{i,t}^{\prime} &= \begin{cases} s_{i,t}, s_{i,t} + b_i \in Topk(\{s_{j,t} + b_j|K_s + 1 \leq j \leq mN\}, mK-K_s), \\ 0, otherwise, \end{cases} \end{align} \]
需要注意的是,偏置项仅用于路由。与FFN输出相乘的门控值仍然来源于原始得分\(s_{i,t}\)。
在训练过程中,持续监控每个训练步骤中整个批次的专家负载。在每个步骤的末尾,如果相应的专家过载,将减少偏置项;如果相应的专家欠载,将增加偏置项。通过动态调整,DeepSeek-V3
在训练期间保持专家负载平衡,并比通过纯辅助损失鼓励负载平衡的模型实现了更好的性能。