【文献阅读】Better & Faster Large Language Models via Multi-token Prediction
论文地址:
DeepSeek-V3使用了多token预测(Multi-token Prediction, MTP)技术,今天来读一下这篇文章。
模型架构
传统的NSP任务一次只会预测一个token,即next token。损失函数如下所示:
\[L_1 = -\sum_tlogP_{\theta}(x_{t+1}|x_{t:1}),\]
而MTP技术则让模型在当前时刻预测后续的\(n\)个token,损失函数如下所示:
\[L_n = -\sum_tlogP_{\theta}(x_{t+n:t+1}|x_{t:1})\]
具体实现如下图:

上图中,每个时刻的token输入都会输出\(n\)(图中\(n\)=4)个预测token:
\[P_{\theta}(x_{t+i}|x_{t:1}),i=1,...,n\]
其中,模型主干是被共享的,每个待预测的token都有一个独立的输出头。这些输出头并行工作,预测对应的未来token。每个输出头后面跟着一个共享的Unembedding层,将Transformer的输出转换成词表空间(vocabulary space)。
内存优化
为了解决多token预测带来的内存消耗问题,论文提出了一种内存高效的实现方法。前向和反向传播顺序调整:在计算梯度时,模型会依次计算每个输出头的梯度,而不是一次性计算所有头的梯度,从而避免了同时存储所有输出头的梯度信息,降低GPU内存占用。
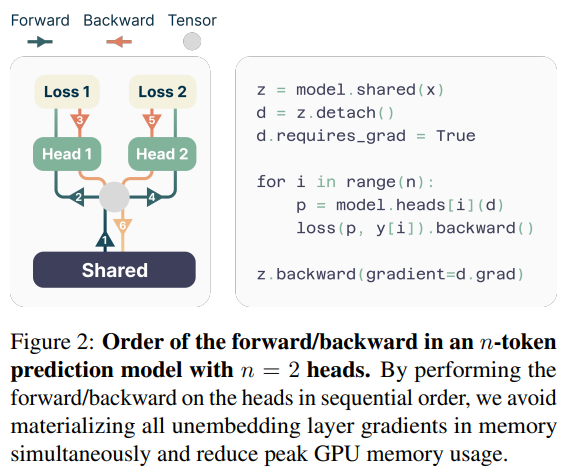
推理加速
最简单的推理方法是只保留第一个输出头,即等效于NSP,只预测下一个token。论文中使用了Self-Speculative Decoding的方法,利用多个输出头加速推理。
- 自推测解码(Self-Speculative Decoding):利用多token预测的额外输出头进行自推测解码,从而加速推理过程。
- 工作原理:先用多个输出头并行预测多个token,然后用主输出头(next-token prediction head)验证预测结果,并选择最有可能的预测结果。