How continuous batching enables 23x throughput in LLM inference while reducing p50 latency
参考https://www.anyscale.com/blog/continuous-batching-llm-inference
The basics of LLM inference
LLM 推理是一个迭代过程,在每个前馈循环后获得一个新的token。例如,如果输入为“What is the capital of California:”,它需要进行十次前馈循环才能得到完整的回答[“S”,“a”,“c”,“r”,“a”,“m”,“e”,“n”,“t”,“o”]。
如下图所示:
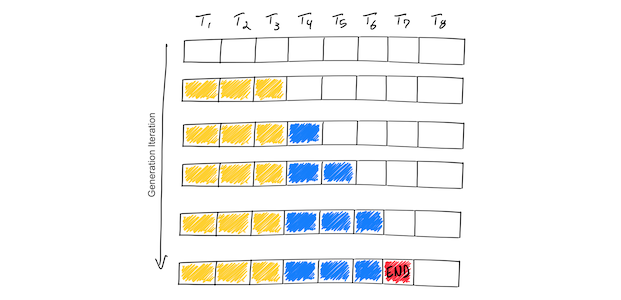
上图示例显示了一个支持最大序列长度为8个标记(T1,T2,…,T8)的推理过程。从Prompt(黄色)开始,迭代过程逐个生成新的token(蓝色)。一旦模型生成了一个结束序列标记(红色),生成循环停止。
LLM batching explained
Naive batching / static batching
我们称下图这种传统的批处理方法为静态批处理,因为批大小在推理完成之前保持不变。
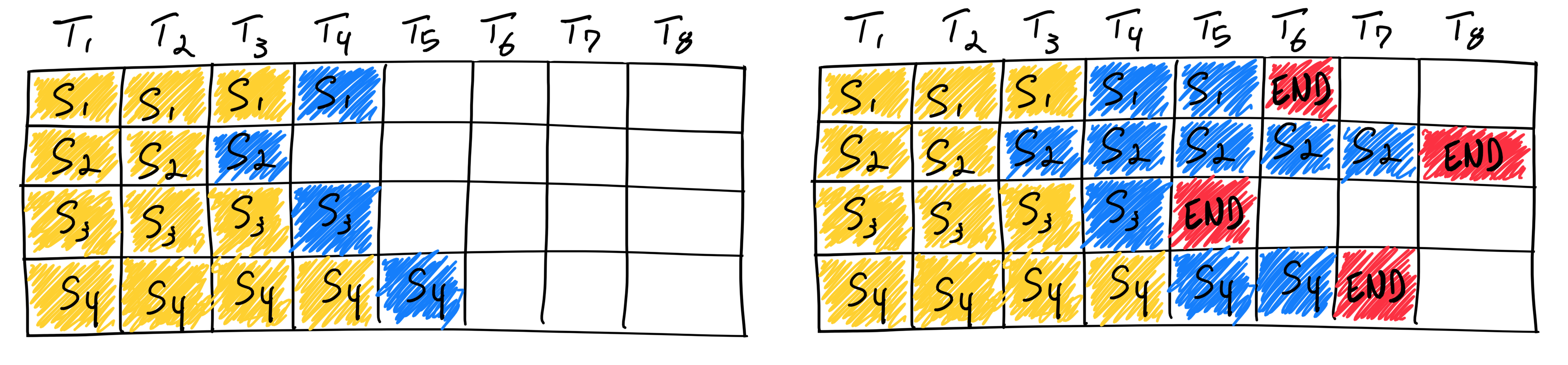
在第一遍迭代(左)中,每个序列从提示词(黄)中生成一个token(蓝)。经过几轮迭代(右)后,完成的序列具有不同的尺寸,因为每个序列会在不同的时刻生成结束标记(红)。
尽管序列3在两次迭代后完成,但静态批处理意味着GPU
将会等到最慢的序列完成生成之后才结束该批次的迭代。
这样,就意味着GPU在等待过程中产生了算力浪费,表示为上图中的白色方块。
Continuous batching
Continuous batching采用了迭代级调度,一旦批中的一个序列完成生成,就可以在其位置插入一个新的序列,从而实现比静态批处理更高的GPU利用率。如下图所示:
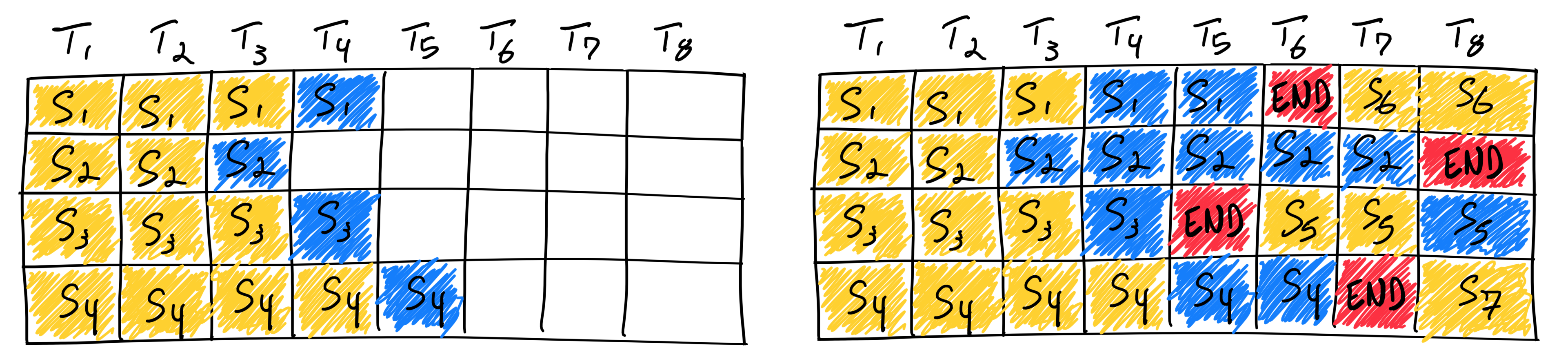
一旦一个序列产生结束序列标记,我们在其位置插入新的序列(即序列S5、S6和S7)。这实现了更高的 GPU 利用率,因为 GPU 不需要等待所有序列完成才开始新的迭代过程。