DeepSeekMoE详解
论文地址:
论文代码:
这篇文章来说DeepSeekMoE算法的原理。
论文地址:
论文代码:
这篇文章来说DeepSeekMoE算法的原理。
在DeepSeek的模型层面,有两个值得关注的点:
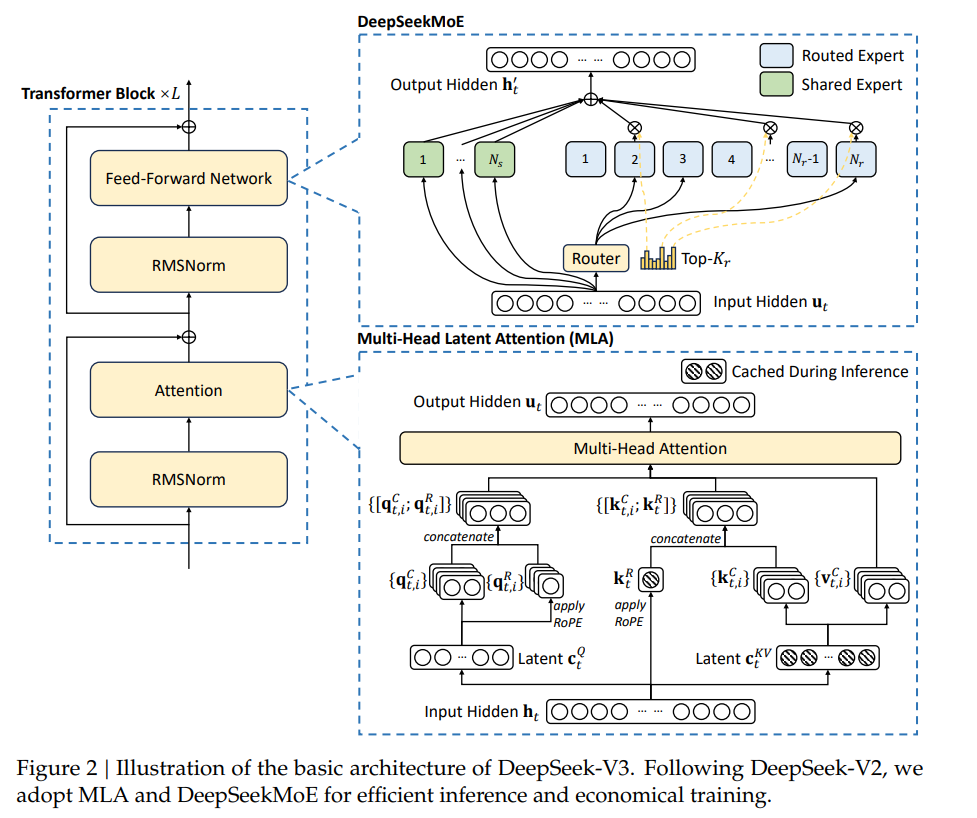
这篇文章先来说第一个部分, MLA(Multi-head Latent Attention)算法的原理。
通过Python传文件。
1 | # 服务端 |
ModernBERT 是一个全新的模型系列,在速度和准确性两个维度上全面超越了 BERT 及其后继模型。这个新模型整合了近年来大语言模型(LLMs)研究中的数十项技术进展,并将这些创新应用到 BERT 风格的模型中。
论文地址:
论文代码:
介绍蒙特卡洛树搜索算法。
论文地址:
对OpenAI o1可能用到的技术进行整理。
MinHash算法和LSH(Locality Sensitive Hashing),用于快速估计两个集合的相似度。它们被广泛应用于大数据集的相似检索、推荐系统、聚类分析中,如今在大模型预训练的数据处理中也有使用到这两个算法。
如何清理过大的Git仓库。
介绍@Resource的配置。