【文献阅读】R-Drop: Regularized Dropout for Neural Networks
论文地址:
论文代码:
R-Drop示意图如下,即同一条文本输入同样的模型两次,通过dropout得到同一条文本不一样的表示(和SimCSE一样)。然后在计算交叉熵损失的同时也计算两个不同表示的KL散度,来使得样本在不同的dropout下也可以得到一致的向量表示,从而提升分类任务的准确性。
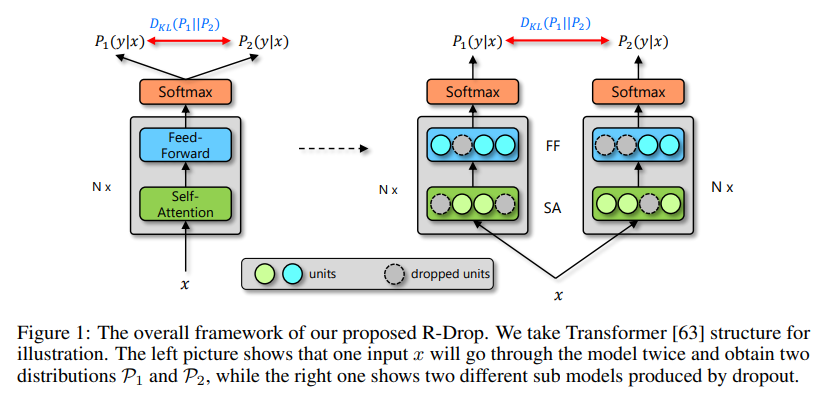
Dropout是典型的训练和预测不一致的方法。具体来说,训练时使用了dropout让某些元素随机为0,预测时将dropout关闭,两者未必等价,这就是Dropout的训练预测不一致问题。
R-Drop通过增加一个正则项,来强化模型对Dropout的鲁棒性,使得不同的Dropout下模型的输出基本一致,因此能降低这种不一致性。
R-Drop算法流程如下:

其中(3)式为交叉熵损失:
\[L_{NLL}^i=-logP_1^w(y_i|x_i)-logP_2^w(y_i|x_i)\]
(2)式为KL散度:
\[L_{KL}^i=\frac{1}{2}(D_{KL}(P_1^w(y_i|x_i)||P_2^w(y_i|x_i))
+ D_{KL}(P_2^w(y_i|x_i))||P_1^w(y_i|x_i))\]
最终损失函数为式(4): \[L^i=L_{NLL}^i + \alpha \cdot L_{KL}^i\]