优化器(optimizer)介绍
介绍SGD、SGDM、Adagrad、RMSProp、Adam等优化器算法
介绍SGD、SGDM、Adagrad、RMSProp、Adam等优化器算法
官方介绍:
MCP 是一个开放协议,用于标准化应用程序向大语言模型提供上下文的方式。可以将 MCP 想象成 AI 应用程序的 USB-C 接口。就像 USB-C 为设备连接各种外设和配件提供了标准化方式一样,MCP 为 AI 模型连接不同的数据源和工具提供了标准化方式。
详解PPO算法和GRPO算法。
Pytorch中AveragedModel实现了随机权重平均 (SWA) 和指数移动平均 (EMA) 的平均模型。
在下面的示例中,swa_model是累积权重平均值的 SWA 模型。我们总共训练模型 300 个时期,并切换到 SWA 学习率计划,并开始在第 160 个时期收集参数的 SWA 平均值:
1 | loader, optimizer, model, loss_fn = ... |
在下面的示例中,ema_model是 EMA 模型,它累积权重的指数衰减平均值,衰减率为 0.999。我们总共训练模型 300 个时期,并立即开始收集 EMA 平均值。
1 | loader, optimizer, model, loss_fn = ... |
论文地址:
DeepSeek-V3使用了多token预测(Multi-token Prediction, MTP)技术,今天来读一下这篇文章。
论文地址:
论文代码:
这篇文章来说DeepSeekMoE算法的原理。
在DeepSeek的模型层面,有两个值得关注的点:
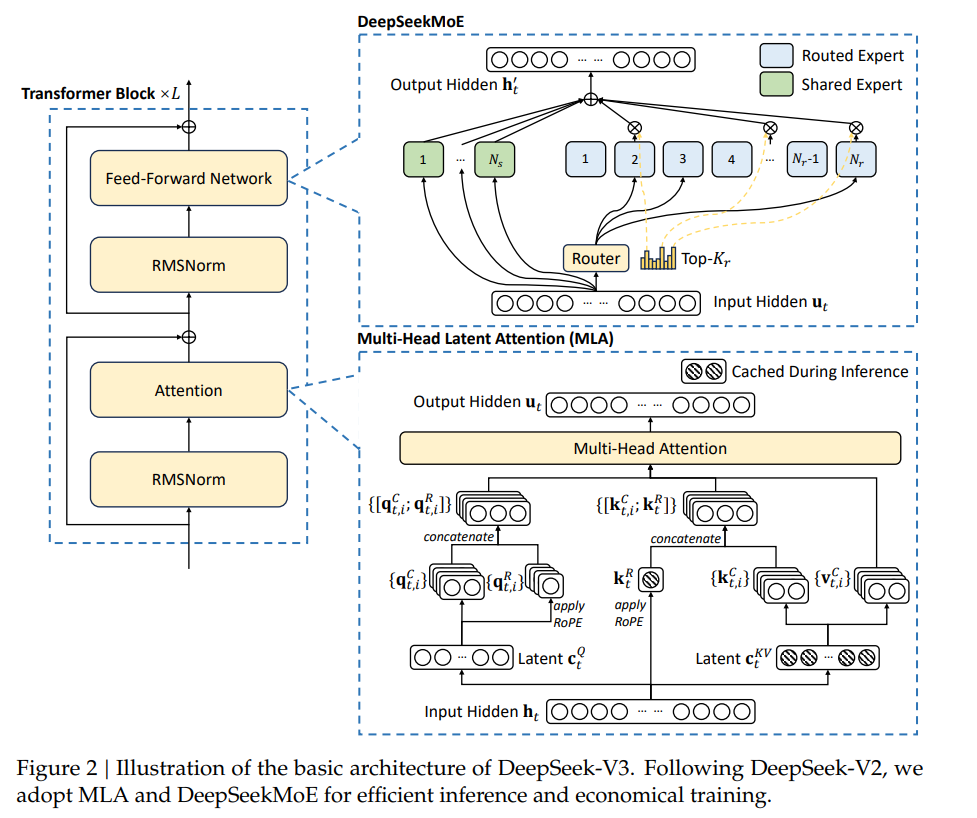
这篇文章先来说第一个部分, MLA(Multi-head Latent Attention)算法的原理。
通过Python传文件。
1 | # 服务端 |
ModernBERT 是一个全新的模型系列,在速度和准确性两个维度上全面超越了 BERT 及其后继模型。这个新模型整合了近年来大语言模型(LLMs)研究中的数十项技术进展,并将这些创新应用到 BERT 风格的模型中。
论文地址:
论文代码: